
IEEE DataPort’s Spring 2020 Dataset Upload Competition Entries
All contest entries will be evaluated and must meet all contest rules in order to be eligible for prizes.

Dataset description:
This contains ten categories of gas data, each category contains 5 concentrations, 10, 20, 30, 40, 50ppm.
There are 160 groups of 10, 20, 30, 40, each group contains 6000 sampled voltage signals, and the sampling frequency is 10HZ.
There are only 80 groups for 50ppm concentration, and each group also contains 6000 sampled voltage signals.
The label corresponding to each gas includes category and concentration, which can be split by gas category and concentration.
- Categories:
 1450 Views
1450 Views
ScanReferr facilitates a clear correspondence between expressions and instances in 3D point cloud scenes, enabling effective identification of target objects. However, the explicit mention of the target object in the expression creates a shortcut that filters out negative samples, aiding model learning. In order to mitigate overreliance on this shortcut, we conducted manual processing of the ScanReferr dataset. Specifically, we replaced the name of the referring object with the term ``object'' while preserving the names of other objects.
- Categories:
8 Views
The Narrative question answering (QA) problem involves generating accurate, relevant, and human-like answers to questions based on the comprehension of a story consisting of logically connected paragraphs. However, this problem remains unexplored for the Arabic language because of the lack of Arabic narrative datasets. To address this gap, we present the Arabic-NarrativeQA dataset, which is the first dataset specifically designed for machine-reading comprehension of Arabic stories.
- Categories:
304 Views
(i) At t = nTp [where n is an integer and Tp (= 1/f) is the period], the LF’s longitudinal vibration velocity and bending vibration displacement reach the peak values along the −x and +z axes, respectively.
- Categories:
119 Views
The "Queue Waiting Time Dataset" is a detailed collection of information that records the movement of waiting times in queues. This dataset contains important details such as the time of arrival, the start and finish times, the waiting time, and the length of the queue. The arrival time denotes the moment when customers enter the queue, while the start and finish times track the duration of the service process. The waiting time measures the time spent waiting in the queue, and the queue length shows the number of customers in the queue when a new customer arrives.
- Categories:
2999 Views
Overview
The dataset under consideration is a comprehensive compilation of code snippets, function descriptions, and their respective binary representations aimed at fostering research in software engineering. It contains a variety of code functionalities and serves as a valuable resource for understanding the behavior and characteristics of C programs. This data is sourced from the AnghaBench repository, a well-documented collection of C programs available on GitHub.
Columns and Data Types
- Categories:
165 Views
This dataset contains the Supplementary Information of the article "Discovering Mathematical Patterns Behind HIV-1 Genetic Recombination: a new methodology to identify viral features" (Manuscript DOI: 10.1109/ACCESS.2023.3311752).
- Categories:
310 Views
We present a finite-element-based cohesive zone model for simulating the nonlinear fracture process driving the propagation of water-filled surface crevasses in floating ice tongues. The fracture process is captured using an interface element whose constitutive behavior is described by a bilinear cohesive law, and the bulk rheology of ice is described by a nonlinear elasto-viscoplastic model. The additional loading due to meltwater pressure within the crevasse is incorporated by combining the ideas of poromechanics and damage mechanics.
- Categories:
304 Views
This paper presents a cost-effective approach for building energy usage management through energy usage optimization of available building energy sources. An energy cost reduction model is developed considering grid energy usage and cost, generator energy usage and cost as well as carbon emissions tax penalties associated with scope 1 emissions. The model selects optimal times to use either Grid energy, generator energy, or a combination of the two to minimize the overall building energy usage cost.
- Categories:
284 Views
In this article, human fatty liver (HFL) volume is measured using the proposed HFL device. The HFL device consists of nano graphene polyvinyl (NGP) sensor and node MCU microcontroller. The NGP sensor acquires electromagnetic radiations from fatty liver (FL), which arise due to dielectric materials in fat. Continuous monitoring of FL volume through various medical imaging instruments leads to frequent exposure of radiation.
- Categories:
242 Views
ARImulti-mic: real-world speech recordings on a humanoid robot (ARI)
This dataset includes “real-world” experiments. A recording campaign was held in the acoustic laboratory at Bar-Ilan University. This lab is a [6×6×2.4]m room with a reverberation time controlled by 60 interchangeable panels covering the room facets.
- Categories:
336 Views
We employed a case study research approach to gather the factors for troubled software projects from the existing literature to generate an innovative dataset. A comprehensive dataset that serves as a foundational reference for future investigations. We extracted incidents from case study data, generated open codes, and organized these open codes into 18 problem categories and 27 solution categories. The mapping between open codes, axial codes and phases is documented in dataset. The codes encapsulate the behavioral patterns or actions of a team that initiate or cause is
- Categories:
Views



The dataset aims to facilitate research in the optimization of the carbon footprint of recipes. Consisting of 30 Excel files processed through various Python scripts and Jupyter notebooks, the dataset serves as a versatile resource for both performance analysis and environmental impact assessment. The unique attribute of this dataset lies in its ability to calculate representative values of carbon footprint optimization through multiple algorithmic implementations.
- Categories:
259 Views
This dataset contains video-clips of five volunteers developing daily life activities. Each video-clip is recorded with a Far InfraRed (FIR) camera and includes an associated file which contains the three-dimensional and two-dimensional coordinates of the main body joints in each frame of the clip. This way, it is possible to train human pose estimation networks using FIR imagery.
- Categories:
526 Views
The dataset is the image data obtained after data conversion of the phases of six Chinese sign languages collected using RFID, the dataset includes the data of five people in environment 1, and also includes the data of user 1 in the previous environment, the dataset is converted into 1000×1000 pixel images to be saved in it, which is a total of 3,000 images.
- Categories:
285 Views
Recognizing and categorizing banknotes is a crucial task, especially for individuals with visual impairments. It plays a vital role in assisting them with everyday financial transactions, such as making purchases or accessing their workplaces or educational institutions. The primary objectives for creating this dataset were as follows:
- Categories:
337 Views
The dataset and source code used in paper "Pick the Better and Leave the Rest: Leveraging Multiple Retrieved Results to Guide Response Generation".
- Categories:
65 Views
We introduce an English Twitter dataset designed for the detection of online drug use, comprising 112,057 tweets accompanied by metadata. This dataset underwent manual annotation by a team of expert annotators consisting of around 30 members, these annotators, possessing diverse multidisciplinary backgrounds and expertise, committed over six months to meticulously label each tweet.
- Categories:
539 Views
This figures show a sequence of photos of puncturing into the zerbrafish embryo. Initially, the tip approached the embryo orthogonally to the slot and punctured into the embryo at the instant that it was in contact with the cell membrane. Subsequently, the USPA caused the tip to retract from the embryo; this process changed the embryo’s position possibly because of the dragging force between the pipette and the membrane [48].
- Categories:
39 Views
Different faults are experienced by a power system, particulary in transmission lines. In this dataset, the IEEE 5-Bus Model was used to different types of transmission line faults.
Indication of the label of the faults come from the time that the fault has been induced in the simulation.
This dataset aims to be utilized for machine learning algorithms, particularly in multi-class classification of the transmission line fault. In this simulation, each fault was induced at each transmission line one instance at a time during a certain period.
- Categories:
1523 Views
TANG FENG: IMAGE PROCESSING AND COMPUTER VISION.
- Categories:
157 Views
The Shining3D dataset consists of 1866, 272, and 272 videos for the training, validation, and testing sets, respectively. The uniform size of the images in the dataset is 640 × 480 pixels. LabelMe software is employed to accurately mark the boundary and classify the region of each tooth in the datasets. This dataset is usef for orthodontic treatment. Orthodontic treatment monitoring, one of the research direction of artificial intelligence, involves using current images and previous 3D models to estimate the relative position of individual teeth before and after orthodontic treatment.
- Categories:
689 Views
Real-time monitoring of heat flux changes in hot-end components in harsh environments is of great significance for safe operation and thermal protection design. Although many high-performance heat flux sensors have been developed on planar by technologies such as MEMS, their inherent planar properties make it difficult to satisfy the characteristics of curved surfaces on real objects.
- Categories:
15 Views
The Aoralscan3 dataset includes 1573, 244, and 244 videos for the corresponding sets. The uniform size of the images in the dataset is 640 × 480 pixels. LabelMe software is employed to accurately mark the boundary and classify the region of each tooth in the datasets. This dataset is usef for orthodontic treatment. which is one of the research direction of artificial intelligence using current images and previous 3D models to estimate the relative position of individual teeth before and after orthodontic treatment.
- Categories:
479 Views
The training set, validation set, and testing set in the constructed Shining3D tooth pose dataset contain 1689, 150, and 150 samples, respectively. Jaw models are generated from hospital patients by oral scanning. The ground truth of the relative pose of each tooth is generated by adding random jittering to the tooth models. For each tooth, ground truth relative pose information was generated by introducing random jittering to the tooth models.
- Categories:
174 Views
The constructed Aoralscan3 tooth registration dataset includes 1667 samples for training, 156 samples for validation, and 176 samples for testing. Jaw models are generated from hospital patients by oral scanning. The ground truth of the relative pose of each tooth is generated by adding random jittering to the tooth models. For each tooth, ground truth relative pose information was generated by introducing random jittering to the tooth models. This dataset can be used for point cloud registration.
- Categories:
127 Views
Just Recognizable Distortion (JRD) refers to the minimum distortion that notably affects the recognition performance of a machine vision model. If a distortion added to images or videos falls within this JRD threshold, the degradation of the recognition performance will be unnoticeable. Based on this JRD property, it will be useful to Video Coding for Machine (VCM) to minimize the bit rate while maintaining the recognition performance of compressed images.
- Categories:
482 Views
This dataset was used to support our work and provided to the review for reference.
- Categories:
102 Views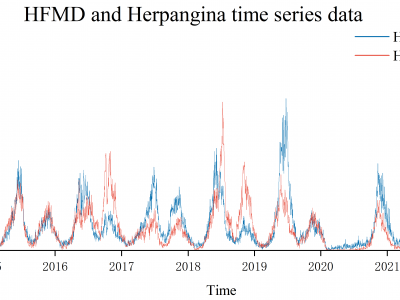
The daily case data for HFMD (Hand-Foot-and-Mouth Disease) and herpangina were collected from the Children’s Hospital of Chongqing Medical University, a national clinical medical research center of China, spanning from January 1, 2015, to December 31, 2021. This dataset contains the timestamp of each patient's discharge, resulting in a total of 109,096 records for HFMD and 133,869 records for herpangina.
- Categories:
213 Views
This dataset provides the data collected in the scope of a Systematic Literature Review (SLR) study that focuses on systematically gather and analyse the existing literature on SOTIF published during 2018-2023. By performing a SLR on SOTIF, we have determine the factors associated with the successful implementation of SOTIF measures, the challenges arise when ensuring SOTIF for ADSs, and research gaps from the SLR of existing literature on SOTIF. The dataset can be useful for the researchers and practitioners.
- Categories:
77 Views
Gamification is a rapidly evolving field that seeks to integrate game mechanics and elements into non-game contexts to enhance the learning experience of computer science students.
- Categories:
845 Views
- Categories:
348 Views
This dataset is from our study that challenges the conventional interpretation of electrocardiogram (ECG) measurements, suggesting a paradigm shift in our understanding. Traditionally, ECGs are seen as reflections of the electric potential on the body's surface, but we propose an alternative hypothesis: ECGs may represent the gradient of the electric potential rather than the potential itself. To investigate this, we use computational methods based on the boundary element method (BEM) within the SCIRun numerical package.
- Categories:
61 Views
Dataset in "Multiple-condition fusion network for characterizing complex subsurface structures based on sparse measurements and auxiliary variable". The data set includes two-dimensional experimental case data and three-dimensional experimental case data. All data used in this study are available at Github repository (https://github.com/GS-3DMG/mcf-net-data) and have been published on Zenodo (https://doi.org/10.5281/zenodo.8260600).
- Categories:
100 Views
Cardiovascular diseases (CVD) are a leading global health concern. Comprehensive data on CVD and key biomarkers play a pivotal role in deciphering individual symptomatology. These biomarkers encompass a range of physiological indicators, such as cholesterol levels, blood pressure, and inflammatory markers like C-reactive protein.
- Categories:
1887 Views
This dataset encompasses cycling experiments conducted on lithium-ion batteries, involving 5 distinct batches, each originating from a different manufacturer. Within each batch, there were 6 batteries subjected to testing. The battery types employed for testing included cylindrical 21700 cells and 18650 type and nickel manganese cobalt or nickel cobalt aluminum.
- Categories:
457 Views
Enterprise green innovation has emerged as an urgent concern for manufacturing companies in the current context of global green and sustainable development. China's "peak carbon emissions" and "carbon neutrality" goals require companies to take proactive measures to reduce carbon emissions and improve energy efficiency, with the application of digital technology playing a crucial role in this process.
- Categories:
176 Views
The first part of the data set contains the monthly recorded spread of covid-19 across the 6 geopolitical zones of Nigeria for the period of March 2020 to September 2022.
The second part of the data set contains the recorded covid-19 spread during religious festivals across the 6 geopolitical zones of Nigeria.
The third part contains the projected population densities of the 36 states of Nigeria alongside the number of covid-19 test centres in each state.
- Categories:
351 Views
Abstract— Spacesuits are essential for ensuring the safety and functionality of astronauts during space missions. However, they can introduce challenges such as sensory deprivation, reduced dexterity, and lower cognitive performance, which can increase the risk of error. In our previous research, we have shown that adding sound transparency to a suit improves cognitive scores with the block design task. Building upon these findings, here we evaluate use of electro haptics feedback in place of traditional haptics.
- Categories:
50 Views
Cyber Threat Intelligence (CTI) Quality Metrics Introduction
This dataset is part of the respective publication regarding the metrics of CTI quality.
License All datasets are available under a GNUv3 General Public License.
- Categories:
1322 Views
Technology`s rapid growth has revolutionized education, inspiring teachers to integrate it into both pedagogical and andragogical approaches.
In order to maintain educational continuity, the pandemic pushed educational institutions and schools all over the world to immediately adopt remote learning and apply numerous digital tools and technology.
Technology has made communication and cooperation between students, instructors, and parents straightforward.
- Categories:
247 Views
Our video action dataset is generated using a 3D simulation program developed in Unity. Each data sample consists of a video capturing a human performing various actions. Our initial set of actions comprises a total of 10 different yoga poses: camel, chair, child's pose, lord of the dance, lotus, thunderbolt, triangle, upward dog, warrior II, and warrior III. Within each of these 10 yoga poses, there are four variations, some exhibiting more pronounced differences than others. This results in a total of 40 action types within our dataset.
- Categories:
123 Views
The Numerical Latin Letters (DNLL) dataset consists of Latin numeric letters organized into 26 distinct letter classes, corresponding to the Latin alphabet. Each class within this dataset encompasses multiple letter forms, resulting in a diverse and extensive collection. These letters vary in color, size, writing style, thickness, background, orientation, luminosity, and other attributes, making the dataset highly comprehensive and rich.
- Categories:
517 Views
Social Media Big Dataset for Research, Analytics, Prediction, and Understanding the Global Climate Change Trends is focused on understanding the climate science, trends, and public awareness of climate change. The use of dataset for analytics of climate change trends greatly helps in researching and comprehending global climate change trends.
- Categories:
4297 Views
Chengdu is one of the largest cities in southwest China and the capital city of Sichuan Province. With a large population and huge transportation needs, public transportation is of vital importance to this city. After years of construction and development, Chengdu's public transportation system has formed a modern multi-level and multi-modal transportation network including buses, subways, railways and BRT (Bus Rapid Transit System). The construction and operation of these transportation systems have provided Chengdu citizens with convenient and fast travel modes.
- Categories:
162 Views
Blood pressure (BP) measurement is an indispensable parameter for diagnosing many diseases, e.g., heart attack, stroke, vascular disease, and kidney disease. All these disease sometimes lead to fatal injuries due to the failure of vital human organs. The measurement of BP using BP device has several inaccuracies due to the non-availability of SI traceable calibration systems, which can also meet the criteria of International Organization of Legal Metrology (OIML) particularly OIML R 148 and OIML R 149 guidelines.
- Categories:
133 ViewsPages
- 1554 reads