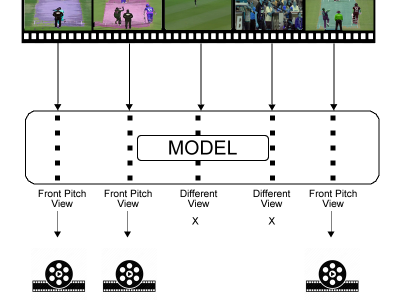
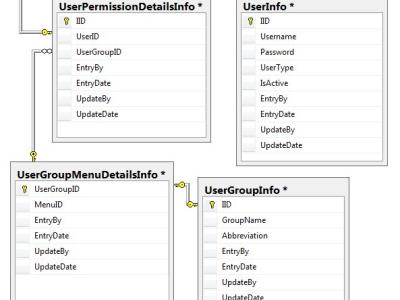
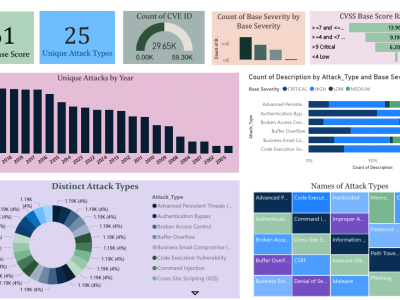
This dataset contains a series of intermediate variables generated during the VVC inter frame encoding process, pattern testing time records, pattern testing history, hierarchical records, and other information. Used for researching fast algorithms between VVC frames
- Categories: