Machine Learning

The Explainable Sentiment Analysis Dataset provides annotated sentiment classification data for Amazon Reviews and IMDB Movie Reviews, facilitating the evaluation of sentiment analysis models with a focus on explainability. It includes ground-truth sentiment labels, model-generated predictions, and fine-grained classification results obtained from various large language models (LLMs), including both proprietary (GPT-4o/GPT-4o-mini) and open-source models (DeepSeek-R1 full and distilled models).
- Categories:
 3 Views
3 Views
The TripAdvisor online airline review dataset, spanning from 2016 to 2023, provides a comprehensive collection of passenger feedback on airline services during the COVID-19 pandemic. This dataset includes user-generated reviews that capture sentiments, preferences, and concerns, allowing for an in-depth analysis of shifting customer priorities in response to pandemic-related disruptions. By examining these reviews, the dataset facilitates the study of evolving passenger expectations, changes in service perceptions, and the airline industry's adaptive strategies.
- Categories:
4 Views
DALHOUSIE NIMS LAB ATTACK IOT DATASET 2025-1 dataset comprises of four prevalent types attacks, namely Portscan, Slowloris, Synflood, and Vulnerability Scan, on nine distinct Internet of Things (IoT) devices. These attacks are very common on the IoT eco-systems because they often serve as precursors to more sophisticated attack vectors. By analyzing attack vector traffic characteristics and IoT device responses, our dataset will aid to shed light on IoT eco-system vulnerabilities.
- Categories:
51 Views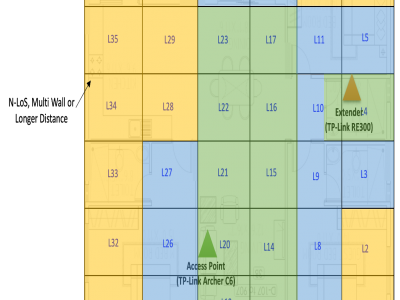
This dataset supports the BWiFi framework, an intelligent method to identify optimal Wi-Fi zones in mesh networks. The home dataset, collected over one month across 36 zones, and the office dataset, collected over two months across 40 zones, systematically measure Wi-Fi quality and application performance metrics. Using clustering techniques and heuristic analysis, BWiFi evaluates zone performance to recommend optimal connectivity areas.
- Categories:
322 Views
This dataset includes spectra of 250 corn samples with different vitality levels, with a data size of 250*256, categorized into five vitality grades. The imaging spectrometer employs a series spectrophotometer, model N17E, with a spectral range of 874-1734nm and a spectral resolution of 5nm. The CCD used is model ICL-B1410, featuring 1600×1200 pixels, and is equipped with an OLES22 lens with a focal length of 22mm.
- Categories:
62 Views
This dataset comprises 33,800 images of underwater signals captured in aquatic environments. Each signal is presented against three types of backgrounds: pool, marine, and plain white. Additionally, the dataset includes three water tones: clear, blue, and green. A total of 12 different signals are included, each available in all six possible background-tone combinations.
- Categories:
256 Views
1.Cora dataset is derived from a multi-group citation network, and the two-group subgraphs are selected for tasks such as graph neural network node classification. The dataset contains sparse Bag-of-Words feature vectors as node attributes, and the labels are mostly academic paper topic categories or fields. This subgraph focuses on the influence of graph structure and node characteristics on model prediction, which provides a reliable experimental benchmark for the research of multi-step adversarial attacks and defense strategies.
- Categories:
26 Views
Reinforcement Learning (RL) has shown excellent performance in solving decision-making and control problems of autonomous driving, which is increasingly applied in diverse driving scenarios. However, driving is a multi-attribute problem, leading to challenges in achieving multi-objective compatibility for current RL methods, especially in both policy execution and policy iteration. We propose a Multi-objective Ensemble-Critic reinforcement learning method with Hybrid Parametrized Action for multi-objective compatible autonomous driving.
- Categories:
17 Views
The presented dataset contains information about struts utilized in a material system, including three key attributes: strut diameter, strut type, and sample number. The strut diameter describes the structural element's physical dimension, whereas the strut type specifies the design or placement inside the material, such as edge configurations. A sample number is assigned to each sample, identifying it uniquely. This data can be used in machine learning systems to forecast material qualities, optimize designs, and investigate the effect of strut configurations on structural performance.
- Categories:
130 Views
This dataset comprises Terahertz (THz) images collected to support the research presented in the IEEE Access paper titled Diagnosing Grass Seed Infestation: Convolutional Neural Network Based Terahertz Imaging. The dataset is intended for the detection and classification of grass seeds embedded in biological samples, specifically ham, covered with varying thicknesses of wool. The images were captured at different frequencies within the THz spectrum, providing valuable data for the development of deep-learning models for seed detection.
- Categories:
16 Views