Communications
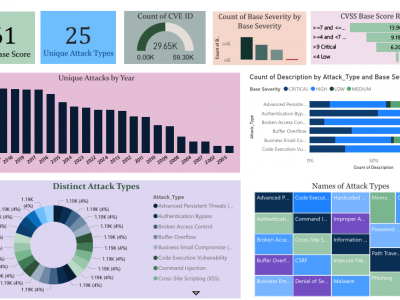
The CyberAlert-25 Dataset is a comprehensive collection of curated cyber threat data, developed to support advanced research in vulnerability detection, classification, and threat intelligence. Aggregated from authoritative sources such as the National Critical Information Infrastructure Protection Center (NCIIPC) and the MITRE Corporation, the dataset focuses on Common Vulnerabilities and Exposures (CVEs), encompassing a total of 29,650 entries.
- Categories:
 30 Views
30 Views
At-sea testing of underwater acoustic communication systems requires resources unavailable to the wider research community, and researchers often resort to simplified channel models to test new protocols. The present dataset comprises in-situ hydrophone recordings of communications and channel probing waveforms, featuring an assortment of popular modulation formats. The waveforms were transmitted in three frequency bands (4-8 kHz, 9-14 kHz, and 24-32 kHz) during an overnight experiment in an enclosed fjord environment, and were recorded on two hydrophone receivers.
- Categories:
92 Views
Astronomical instrumentation and related fields have seen remarkable evolution in recent decades, driving the need for advanced signal acquisition and processing techniques. Current experiments demand readout capabilities beyond traditional approaches, leading to the adoption of a wideband instrumentation system architecture for high-speed Radio Frequency (RF) measurements. Field Programmable Gate Array (FPGA) and System on Chip (SoC) devices, owing to their features, are well-suited to perform tasks related to the digital back-end of these types of systems.
- Categories:
148 Views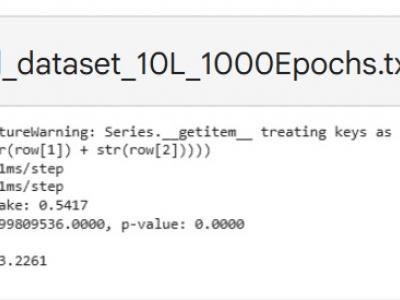
This paper explores the cryptanalysis of the ASCON algorithm, a lightweight cryptographic method designed for applications like the Internet of Things (IoT). We utilize deep learning techniques to identify potential vulnerabilities within ASCON's structure. First, we provide an overview of how ASCON operates, including key generation and encryption processes.
- Categories:
156 Views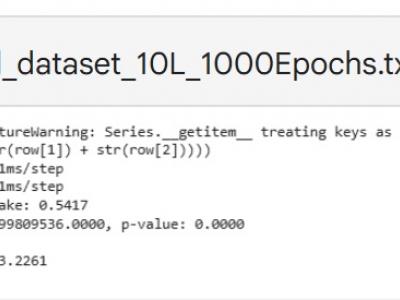
This paper explores the cryptanalysis of the ASCON algorithm, a lightweight cryptographic method designed for applications like the Internet of Things (IoT). We utilize deep learning techniques to identify potential vulnerabilities within ASCON's structure. First, we provide an overview of how ASCON operates, including key generation and encryption processes.
- Categories:
35 Views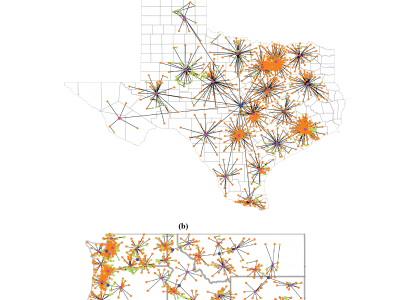
Modern power systems face growing risks from cyber-physical attacks, necessitating enhanced resilience due to their societal function as critical infrastructures. The challenge is that defense of large-scale systems-of-systems requires scalability in their threat and risk assessment environment for cyber-physical analysis including cyber-informed transmission planning, decision-making, and intrusion response. Hence, we present a scalable discrete event simulation tool for analysis of energy systems, called DESTinE.
- Categories:
195 Views
Network Interface Cards (NICs) are one of the key enablers of the modern-day Internet. They serve as gateways for connecting computing devices to networks for the exchange of data with other devices. Recently, the pervasive nature of Internet-enabled devices coupled with the growing demands for faster network access have necessitated the enhancement of NICs to Smart NICs (SNICs), capable of processing enormous volumes of data at near real-time speed.
- Categories:
36 Views
This work presents a dataset based on multiple network and service metrics (KPIs and KQIs), the latest providing the E2E conditions of video on demand service. Particularly, the dataset also includes an attack situation where an attacker injects traffic into the network. In total, there are 3600 samples, with different configurations of Physical Resource Blocks and cell gain, from sessions of 60 seconds.
- Categories:
82 Views
This dataset presents approximately 200 hours of network traffic captures focused on online gaming and video streaming applications, addressing 5G-related challenges of high throughput and low latency. Collected in Ottawa, Canada, and globally from 11 mobile operators across nine countries, the data includes timestamps, packet lengths (bytes), protocols, and IP addresses. Supplementary information such as geolocation, content provider labels, and round-trip latency (ms) enhances usability.
- Categories:
266 Views
This dataset contains results and scripts from experiments evaluating the resilience of the QUIC protocol against handshake flooding attacks. It aims to support researchers and developers in analyzing the performance of QUIC against handshake flooding attacks. The experiments utilize three prominent QUIC implementations: aioquic, quic-go, and picoquic, providing a comprehensive comparison of their resilience. Additionally, to benchmark the performance and resilience of QUIC, SYN flood attacks were conducted against TCP with SYN cookies.
- Categories:
215 Views