
This dataset supports the research on the "Bed Stories" information retrieval system, designed to help children retrieve relevant story content based on semantic query expansion using WordNet ontology.
- Categories:
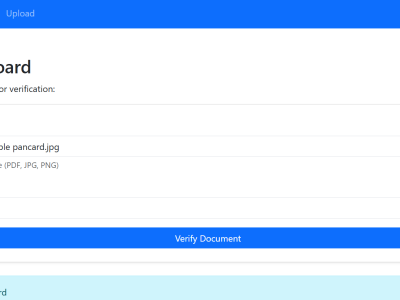
In today’s digital ecosystem, verifying the authenticity of identity documents is essential for secure access control and digital trust. Sectors such as finance, education, government, and employment frequently rely on scanned or digital versions of documents like Aadhaar cards, PAN cards, Voter IDs, Driving Licenses, and Passports. However, this convenience introduces risks related to document forgery and fraudulent activity.

This opinion explores the integration of Artificial Intelligence in foreign language education, examining both its potential benefits and inherent risks. AI tools offer personalized learning experiences, interactive practice, and access to authentic resources, potentially reducing learning-related stress. However, over-reliance on AI may hinder critical thinking and raise concerns about accuracy, originality, and ethical considerations like algorithmic bias. A balanced approach is crucial, emphasizing the importance of academic integrity, ethical conduct, and responsible technology use.
This dataset contains raw survey data collected from 207 Generation Z students at the University of Guelma, Algeria. The data was gathered via an online questionnaire to investigate the adoption of short educational videos for academic purposes in higher education, based on an extended Unified Theory of Acceptance and Use of Technology 2 (UTAUT2) model.
The dataset includes responses for variables representing the following constructs from the extended UTAUT2 model and related factors:
Human Body is an extremely intricate and modern structure and involves a huge number of capacities. All these muddled capacities have been comprehended by man him, part-by-part their exploration and tests. As science and innovation advanced, pharmaceutical turned into a necessary part of the exploration. Continuously, restorative science turned into an altogether new branch of science. Starting today, the Health Sector involves Medical establishments i.e. Healing facilities, HOSPITALs and so forth innovative work foundations and medicinal universities.
Human Body is an extremely intricate and modern structure and involves a huge number of capacities. All these muddled capacities have been comprehended by man him, part-by-part their exploration and tests. As science and innovation advanced, pharmaceutical turned into a necessary part of the exploration. Continuously, restorative science turned into an altogether new branch of science. Starting today, the Health Sector involves Medical establishments i.e. Healing facilities, HOSPITALs and so forth innovative work foundations and medicinal universities.
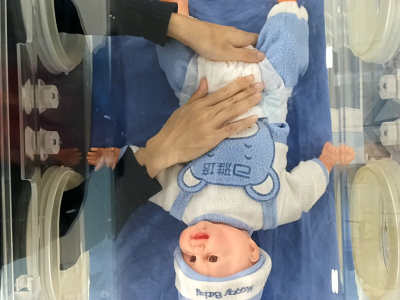
NICU-Care is a high-quality video dataset designed to support visual recognition tasks in Neonatal Intensive Care Unit (NICU) scenarios, including nursing action recognition, object detection, and semantic segmentation. It was constructed in a standardized simulated NICU environment, capturing multi-view RGB videos of professional nurses performing six types of routine caregiving procedures on simulated infants. The dataset provides fine-grained temporal annotations and pixel-level segmentation masks for key objects like nurse hands, medical tools, and infant body parts.
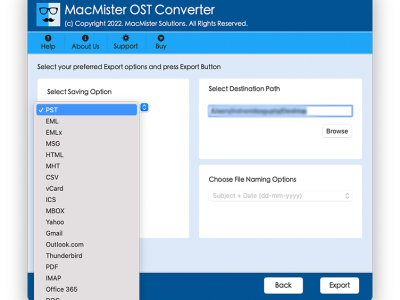
Hey users, if you’re looking for the best tool to convert OST to PST on macOS, then I recommend you utilize the MacMister Mac OST to PST Converter that is the best application to export your limitless OST files into PST format at once. This app permits you to move all your calendars, contacts, emails, notes, journals and more items to PST file format without difficulty. Its highly suggested by most IT experts. With this utility, you can transfer OST files of any size; there is no size restriction. It is compatible with every single version of macOS, Win OS, and Outlook.


The integration of artificial intelligence (AI) in the teaching of English as a Foreign Language (EFL) is on the rise alongside technological progress. This implementation is founded on various contemporary theories that have become central in academia, particularly regarding non-native speakers. These theories encompass sociocultural approaches, connectivism, and adaptive learning, which work in conjunction with AI’s capacity to tailor learning experiences and enhance language engagement.