
Our datasets_PAGML isbased on two public benchmark datasets SHREC2013 and SHREC2014. Sketches are the same as the original datasets. Each 3D shape in the the original datasets is represented as 12 views.
- Categories:
Our datasets_PAGML isbased on two public benchmark datasets SHREC2013 and SHREC2014. Sketches are the same as the original datasets. Each 3D shape in the the original datasets is represented as 12 views.

This dataset is composed by both real and sythetic images of power transmission lines, which can be fed to deep neural networks training and applied to line's inspection task. The images are divided into three distinct classes, representing power lines with different geometric properties. The real world acquired images were labeled as "circuito_real" (real circuit), while the synthetic ones were identified as "circuito_simples" (simple circuit) or "circuito_duplo" (double circuit). There are 348 total images for each class, 232 inteded for training and 116 aimed for validation/testing.

this is a test
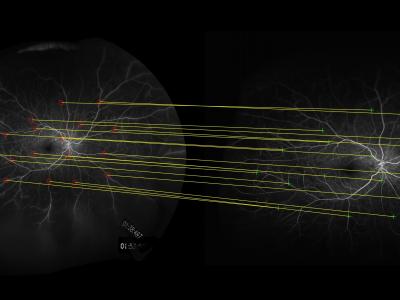
The FLoRI21 dataset provides ultra-widefield fluorescein angiography (UWF FA) images for the development and evaluation of retinal image registration algorithms. Images are included across five subjects. For each subject, there is one montage FA image that serves as the common reference image for registration and a set of two or more individual ("raw") FA images (taken over multiple clinic visits) that are target images for registration. Overall, these constitute 15 reference-target image pairs for image registration.

The PS_Sculpture training dataset introduced by the PS-FCN [1] contains various non-Lambertian reflectances, cast shadows, interreflections and effective noise information. However, for dark materials such as black-phenolic and steel, significant data loss happens due to 8-bit quantification. To lessen this data loss, we design a new supplementary training dataset rendered by 10 blobby objects and 10 other objects freely downloaded from the Internet and the real BRDF data comes from the MERL dataset [2].
These simulated live cell microscopy sequences were generated by the CytoPacq web service https://cbia.fi.muni.cz/simulator [R1]. The dataset is composed of 51 2D sequences and 41 3D sequences. The 2D sequences are divided into distinct 44 training and 7 test sets. The 3D sequences are divided into distinct 34 training and 7 test sets. Each sequence contains up to 200 frames.
Data augmentation is commonly used to increase the size and diversity of the datasets in machine learning. It is of particular importance to evaluate the robustness of the existing machine learning methods. With progress in geometrical and 3D machine learning, many methods exist to augment a 3D object, from the generation of random orientations to exploring different perspectives of an object. In high-precision applications, the machine learning model must be robust with respect to the small perturbations of the input object.

Datasets for image and video aesthetics
1. Video Dataset : 107 videos
This dataset has videos that can be framed into images.
Color contrast,Depth of Field[DoF],Rule of Third[RoT] attributes
that affect aesthetics can be extracted from the video datasets.
2.Slow videos and Fast videos can be assessed for motion
affecting aesthetics

Please cite the following paper when using this dataset:
N. Thakur, "Twitter Big Data as a Resource for Exoskeleton Research: A Large-Scale Dataset of about 140,000 Tweets from 2017–2022 and 100 Research Questions", Journal of Analytics, Volume 1, Issue 2, 2022, pp. 72-97, DOI: https://doi.org/10.3390/analytics1020007
Abstract

Skeleton datasets for Normal, Antalgic, Stiff legged, Lurching, Steppage, and Trendelenburg gaits.