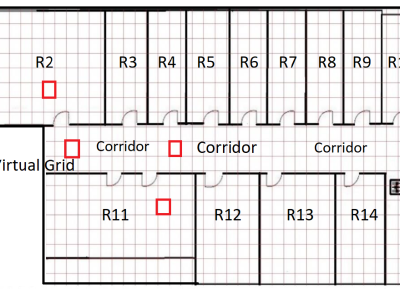
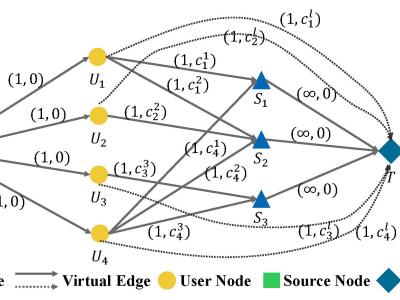
The shift towards cloud-native applications has been accelerating in recent years. Modern applications are increasingly distributed, taking advantage of cloud-native features such as scalability, flexibility, and high availability. However, this evolution also introduces various security challenges. From a networking perspective, the large number of interconnected components and their intricate communication patterns make detecting and mitigating traffic anomalies a complex task.
- Categories: