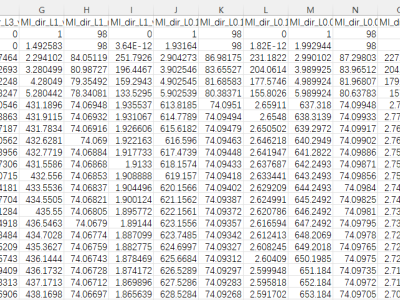
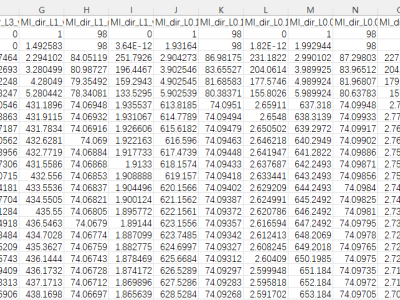
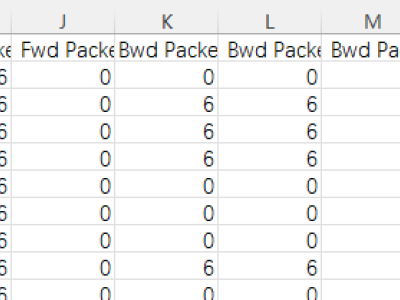
The main goal of this research is to propose a realistic benchmark dataset to enable the development and evaluation of Internet of Medical Things (IoMT) security solutions. To accomplish this, 18 attacks were executed against an IoMT testbed composed of 40 IoMT devices (25 real devices and 15 simulated devices), considering the plurality of protocols used in healthcare (e.g., Wi-Fi, MQTT and Bluetooth).
- Categories: