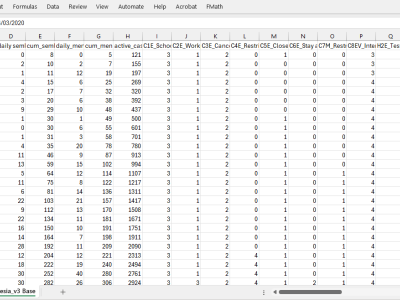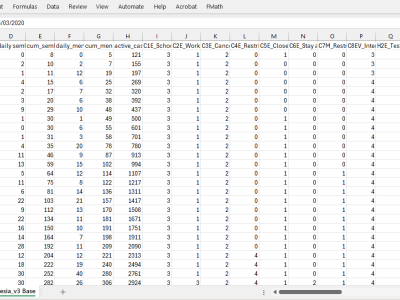
The dataset contains 877 records with 67 variables, documenting various COVID-19-related indicators in Indonesia. The data spans daily case statistics, including new cases, cumulative cases, recoveries, and fatalities. It also tracks government response measures, such as school and workplace closures, public event restrictions, travel controls, and mask mandates. Additionally, it includes vaccination statistics, government response indices, and mobility changes in different sectors (retail, workplaces, and residential areas).
- Categories: