Discrete-time signal processing

The proliferation of efficient edge computing has enabled a paradigm shift of how we monitor and interpret urban air quality. Coupled with the dense spatiotemporal resolution realized from large-scale wireless sensor networks, we can achieve highly accurate realtime local inference of airborne pollutants. In this paper, we introduce a novel Deep Neural Network architecture targeted at latent time-series regression tasks from continuous, exogenous sensor measurements, based on the Transformer encoder scheme and designed for deployment on low-cost power-efficient edge processors.
- Categories:
 1268 Views
1268 Views
This dataset is used to design patent. The system is basic , as can be seen from figure.
There is related dataset- Data: 255W Panel Connected 72Ah Li-Ion.
This new datasets are needed to show that I know how to make simulation and the dataset of 'Data: 255W Panel Connected 72Ah Li-Ion' is not fake.
The boost converter, BMS is on existing designs.It is very simple for any graduate,degree holder or school students, so no paper is written for it.
- Categories:
742 Views
In this appendix, the tested implementation in Matlab of our 2D-TDOA localization algorithm is given for the easier repetition of the obtained results and the future hardware implementation, due to the complexity of the formulas (25)-(31).
- Categories:
491 Views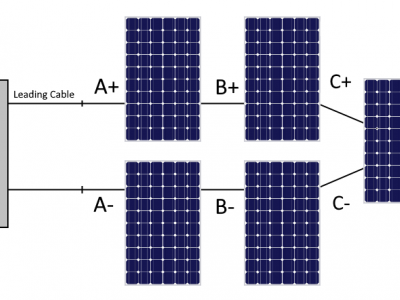
This dataset was used to quantify the effects of environmental change on SSTDR measurements from solar panels. We collect illuminance (Lux), temperature (deg F), and humidity (%) alongside SSTDR waveforms on a fault free string. Data is collected once per minute in January 2020, and twice per minute in August-September 2020.
- Categories:
135 Views
This is a dataset is an example of a distribution of 20 correlated Bernoulli random variables.
- Categories:
380 Views
Three raw (i.e., In-Phase and Quadrature data with a software radio, and observation files) GNSS dataset were recorded using a LabSat Version 3 inside of the West Virginia University greenhouse and two outside recordings were also made to provide a quality reference and comparison. The outdoor location had to be an ideal location for satellite signal reception and the indoor location was a greenhouse room where satellite visibility was limited, susceptible to attenuation, occlusion and multipath.
- Categories:
761 Views
A qualitative and quantitative extension of the chaotic models used to generate self-similar traffic with long-range dependence (LRD) is presented by means of the formulation of a model that considers the use of piecewise affine onedimensional maps. Based on the disaggregation of the temporal series generated, a valid explanation of the behavior of the values of Hurst exponent is proposed and the feasibility of their control from the parameters of the proposed model is shown.
- Categories:
178 Views
This article explores the required amount of time series points from a high-speed computer network to accurately estimate the Hurst exponent. The methodology consists in designing an experiment using estimators that are applied to time series addresses resulting from the capture of high-speed network traffic, followed by addressing the minimum amount of point required to obtain in accurate estimates of the Hurst exponent.
- Categories:
372 Views
Dataset asscociated with a paper in Computer Vision and Pattern Recognition (CVPR)
"Object classification from randomized EEG trials"
If you use this code or data, please cite the above paper.
- Categories:
2349 Views
We provide a public available database for arcing event detection. We design a platform for arcing fault simulation. The arc simulation is carried out in our local lab under room temperature. A general procedure to collect the arcing and normal current and voltage wave, is designed, which consists of turning on the load, generating arc, stoping arc, turning off the load. The data is collected by a 16bit, 10KHz high resolution recorder and a 12bit, 64000Hz low resolution sensor.
- Categories:
775 Views