Smart Grid

This data provides the simulation parameters and the optimal results of the comprehensive active distribution network (ADN) expansion planning model that includes both wire alternatives (WAs) and nonwire alternatives (NWAs). The primary motivation is to find the optimal sizing and siting of NWAs while considering WAs such that the ADN’s dynamically growing electrical load and electrical vehicle (EV) demand are met while maintaining network limits.
- Categories:
 396 Views
396 Views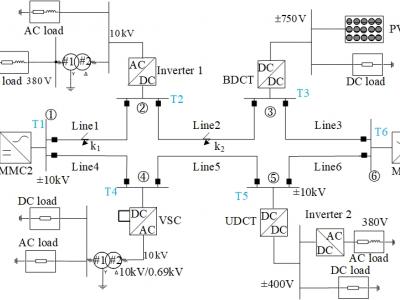
To verify the proposed protection scheme, the simulation model of a six-terminal ring flexible DC distribution system is built in PSCAD/EMTDC , where the rated voltage of the DC line is ±10 kV . The fault inception is set at 0.6 s, the sampling frequency is 10 kHz and the protection data window length is 1 ms. The data set reflects the current and voltage values of each line after standardization
- Categories:
176 Views
The Advanced Metering Infrastructure is established in Electrical Drives Laboratory, School of Electrical and Electronics Engineering, SASTRA Deemed to be University, Thanjavur, Tamil Nadu,India. Further, the ARP spoofing attack emulation is deliberated between Smart Meter and Data Concentrator through the Ettercap tool in two different test beds by incorporating Modbus TCP/IP and MQTT.Then, the benign and malicious traffic patterns of two protocols are captured using Wireshark to form the dataset.
- Categories:
739 Views
In the digital era of the Industrial Internet of Things (IIoT), the conventional Critical Infrastructures (CIs) are transformed into smart environments with multiple benefits, such as pervasive control, self-monitoring and self-healing. However, this evolution is characterised by several cyberthreats due to the necessary presence of insecure technologies. DNP3 is an industrial communication protocol which is widely adopted in the CIs of the US. In particular, DNP3 allows the remote communication between Industrial Control Systems (ICS) and Supervisory Control and Data Acquisition (SCADA).
- Categories:
5361 Views
This dataset is in support of my research paper - Short Circuit Analysis of 666 Wh Li-Ion NMC
Faults and datasets can be copied to submit in fire cause investigation reports or thesis. The simulation is run for 20 hours (72000 seconds) of simulation time for each fault of 100 faults.
PrePrint : (Make sure you have read Caution.)
- Categories:
2462 Views
This dataset is used to design patent and many machines can be designed using this dataset.
This is a very important dataset to do breakthrough. One of the secrets behind invention is revealed in these datasets.
Part of this design, with manually done tabulated calculations were submitted as the proposal design (for innovation challenge) proposed by the author, in the small concept paper to Ministry of Railways, Govt. of India in the year 2017.
As the Excel files(using LibreOffice) are given, so no paper is written is for it.
- Categories:
1922 Views
This dataset has been used to assist in designing patent.
Related Claim : Novel ß Non-Linear Theory, Novel ß Inverter and Novel ß PFC in Patent 'Novel ß 10-Axis Grid Compatible Multi-Controller'
The system is basic, on existing designs.It is very simple for any graduate,degree holder, so no paper is written for it.
- Categories:
831 Views
Single line diagram of the CTPN2.
- Categories:
64 Views
The evolution of the Industrial Internet of Things (IIoT) introduces several benefits, such as real-time monitoring, pervasive control and self-healing. However, despite the valuable services, security and privacy issues still remain given the presence of legacy and insecure communication protocols like IEC 60870-5-104. IEC 60870-5-104 is an industrial protocol widely applied in critical infrastructures, such as the smart electrical grid and industrial healthcare systems.
- Categories:
7901 Views
This data file provides the MATLAB code to reconfigure the distribution networks using a fast and simple two-stage heuristic approach.
- Categories:
395 Views