Computer Vision

The "Sanskrit Character Dataset" includes 44 classes of handwritten Sanskrit characters, designed to support research in optical character recognition (OCR) and machine learning for ancient languages. Each class represents a unique Sanskrit letter, collected in various handwriting styles to ensure diversity and robustness. For each class, 50 to 80 images are included. To ensure diversity and real-world applicability, the letters were written in various handwriting styles.
- Categories:
 302 Views
302 Views
The Tunnel Cable Fire dataset is derived experimentally, this dataset contains images of cable flames at different stages, different cable layers, and different wind speeds, with a special focus on computer vision tasks such as fire detection and segmentation. These images have been enhanced with mosaic data for a total of 1812 datasets, including single and double layer cable fire images in the case of no wind and wind speed of 2.7m/s.
- Categories:
301 Views
Most existing machine learning classifiers are highly vulnerable to adversarial examples. An adversarial example is a sample of input data which has been modified very slightly in a way that is intended to cause a machine learning classifier to misclassify it. In many cases, these modifications can be so subtle that a human observer does not even notice the modification at all, yet the classifier still makes a mistake.
- Categories:
49 Views
现有的公开数据集往往存在数据量小,训练过程不充分,导致过拟合严重,泛化性能差的问题。针对这一问题,构建了雷达数据集 RadSet。在数据获取阶段,frequency modulated continuous wave (FMCW) radar system IWR1843 Boost manufactured by Texas Instruments (TI) was used. The RadSet dataset is collected by I+ Lab at Shandong University, covering a rectangular area 5 meters long in front of the radar and 4 meters wide, with the radar placed at a height of 120 cm above the ground. The volunteers execute the aforementioned activities at distances ranging between 1 to 5 meters from the radar.
- Categories:
232 Views
This Dataset is a self-harm dataset developed by ZIOVISION Co. Ltd. It consists of 1,120 videos. Actors were hired to simulate self-harm behaviors, and the scenes were recorded using four cameras to ensure full coverage without blind spots. Self-harm behaviors in the dataset are limited to "cutting" actions targeting specific body parts. The designated self-harm areas include the wrists, forearms, and thighs.
The full dataset can be accesssed through https://github.com/zv-ai/ZV_Self-harm-Dataset.git
- Categories:
68 Views
The proper evaluation of food freshness is critical to ensure safety, quality along with customer satisfaction in the food industry. While numerous datasets exists for individual food items,a unified and comprehensive dataset which encompass diversified food categories remained as a significant gap in research. This research presented UC-FCD, a novel dataset designed to address this gap.
- Categories:
384 Views
Brain tumors are among the most severe and life-threatening conditions affecting both children and adults. They constitute approximately 85-90% of all primary Central Nervous System (CNS) tumors, with an estimated 11,700 new cases diagnosed annually. The 5-year survival rate for individuals with malignant brain or CNS tumors is alarmingly low, at 34% for men and 36% for women. Brain tumors are categorized into various types, including benign, malignant, and pituitary tumors.
- Categories:
541 Views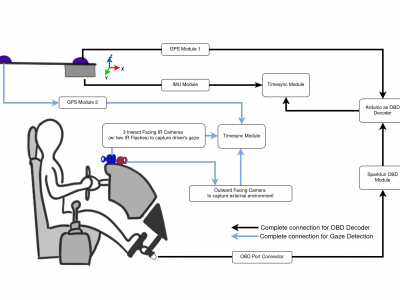
Repeated Route Naturalistic Driving Dataset (R2ND2) is a dual-perspective dataset for driver behavior analysis constituent of vehicular data collected using task-specific CAN decoding sensors using OBD port and external sensors, and (b) gaze-measurements collected using industry-standard multi-camera gaze calibration and collection system. Our experiment is designed to consider the variability associated with driving experience that depends on the time of day and provides valuable insights into the correlation of these additional metrics on driver behavior.
- Categories:
460 Views
This dataset is image data generated by matlab simulation based on star catalog, imaging process analysis, and space target characterization. There are three signal-to-noise ratios in the dataset, the signal-to-noise ratios are 0.7, 1, and 1.5.There are 10 groups of data under each signal-to-noise ratio, and each group of data contains 10 images. It can be used for research such as target detection and tracking.
- Categories:
225 Views
RSHIP137 is a self-built remote sensing dataset of ships, consisting of 119,330 images across 137 categories. The size of each image varies, with the largest having dimensions of 182x699 and the smallest being 7x11. The distribution of categories is highly imbalanced, with the most frequent category being "Barge," which contains 31,466 images, and the least frequent category being "901-fast combat support ship," with only 15 images.
- Categories:
58 Views