Computer Vision

The dataset is a self-constructed wafer surface defect dataset, with each image captured in real-time. The extraction and segmentation of wafer image have been performed, and each image represents a single individual die. The dataset primarily includes images of defect-free dies, as well as four types of defective images: particle, scratch, stain, and liquid residual. A total of 500 images are included, and the various types of defects within the images have been annotated using the Make Sense online annotation tool.
- Categories:
 633 Views
633 Views
The Reflectance Transformation Imaging dataset consists of 32 images from the squeeze of the inscription "Hymn of Kouretes" or "Hymn of Palaikastron" (fragment A, side A) which is hosted at the Archaeological Museum of Heracleon, Crete. The resulting .PTM file is also available, which opens with the free software RTI Viewer.
- Categories:
254 Views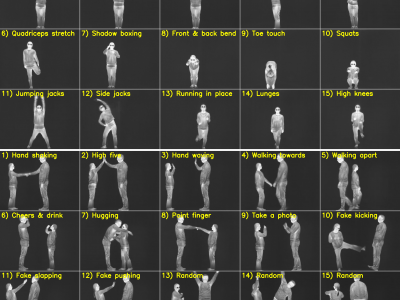
Human pose estimation has applications in numerous fields, including action recognition, human-robot interaction, motion capture, augmented reality, sports analytics, and healthcare. Many datasets and deep learning models are available for human pose estimation within the visible domain. However, challenges such as poor lighting and privacy issues persist. These challenges can be addressed using thermal cameras; nonetheless, only a few annotated thermal human pose datasets are available for training deep learning-based human pose estimation models.
- Categories:
413 Views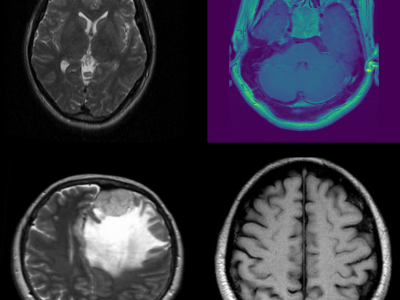
This dataset consists of MRI images of brain tumors, specifically curated for tasks such as brain tumor classification and detection. The dataset includes a variety of tumor types, including gliomas, meningiomas, and glioblastomas, enabling multi-class classification. Each MRI scan is labeled with the corresponding tumor type, providing a comprehensive resource for developing and evaluating machine learning models for medical image analysis. The data can be used to train deep learning algorithms for brain tumor detection, aiding in early diagnosis and treatment planning.
- Categories:
3157 Views
CAPG Grocery Product (CAPG-GP) is a grocery product dataset with 102 fine-grained classes. We organize these 102 classes into five categories based on brands to create hierarchical labels. The original CAPG-GP dataset was first published in 'Fine-Grained Grocery Product Recognition by One-Shot Learning' by Geng et al. in 2018. The original dataset is publicly available at http://zju-capg.org/capg-gp.html.
- Categories:
90 Views
The ICRA conference is celebrating its 40th anniversary in Rotterdam in September 2024, with as highlight the Happy Birthday ICRA Party at the iconic Holland America Line Cruise Terminal. One month later the IROS conference will take place, which will include the Earth Rover Challenge. In this challenge open-world autonomous navigation models are studied truly open-world settings.
- Categories:
179 Views
Smart focal-plane and in-chip image processing has emerged as a crucial technology for vision-enabled embedded systems with energy efficiency and privacy. However, the lack of special datasets providing examples of the data that these neuromorphic sensors compute to convey visual information has hindered the adoption of these promising technologies.
- Categories:
183 Views
Grasping and manipulating objects is an important human skill. Since hand-object contact is fundamental to grasping, capturing it can lead to important insights. However, observing contact through external sensors is challenging because of occlusion and the complexity of the human hand. We present ContactDB, a novel dataset of contact maps for household objects that captures the rich hand-object contact that occurs during grasping, enabled by use of a thermal camera. Participants in our study grasped 3D printed objects with a post-grasp functional intent.
- Categories:
171 Views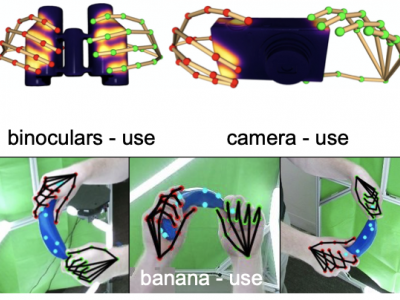
Grasping is natural for humans. However, it involves complex hand configurations and soft tissue deformation that can result in complicated regions of contact between the hand and the object. Understanding and modeling this contact can potentially improve hand models, AR/VR experiences, and robotic grasping. Yet, we currently lack datasets of hand-object contact paired with other data modalities, which is crucial for developing and evaluating contact modeling techniques. We introduce ContactPose, the first dataset of hand-object contact paired with hand pose, object pose, and RGB-D images.
- Categories:
575 Views
Infrared dim-small target detection has gained increasing importance in both military and civilian applications due to its ability to detect thermal radiation, operate effectively at night, passively sense radiation, and offer strong concealment with high resistance to interference. These capabilities make it ideal for systems such as aircraft and bird surveillance, missile guidance, and maritime rescue operations. In these applications, the need for mid- to long-range observations often results in small targets that appear dim and are difficult to detect.
- Categories:
561 Views