Computer Vision

This dataset, titled "Synthetic Sand Boil Dataset for Levee Monitoring: Generated Using DreamBooth Diffusion Models," provides a comprehensive collection of synthetic images designed to facilitate the study and development of semantic segmentation models for sand boil detection in levee systems. Sand boils, a critical factor in levee integrity, pose significant risks during floods, necessitating accurate and efficient monitoring solutions.
- Categories:
 342 Views
342 Views
This dataset presents the recognition of handwritten hieroglyphic alphabets. In this dataset we use consisting of 18 distinct classes of hieroglyphs alphabets. The dataset is designed to facilitate research in the field of ancient script recognition, particularly focusing on handwriting variability and pattern recognition. Each class represents a unique hieroglyph, with samples collected to ensure a diverse range of writing styles. To create this dataset, 25 students each handwrote samples for all 18 classes of hieroglyphs. Afterward, we carefully photographed each image.
- Categories:
424 Views
The SynoClip dataset is a standard dataset specifically prepared for the video synopsis task, featuring videos that represent real-world surveillance conditions. It includes six videos, with durations ranging from 8 to 45 minutes, captured from outdoor-mounted surveillance cameras. Each video comes with manually annotated tracking information, enabling direct comparisons between different video synopsis models.
- Categories:
87 Views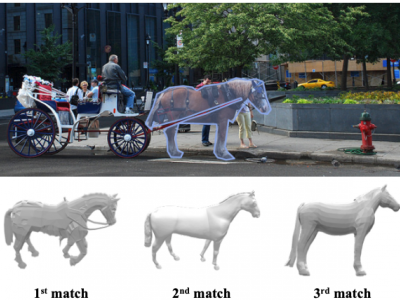
3D-COCO is a dataset composed of MS COCO images with 3D models aligned on each instance. 3D-COCO was designed to achieve computer vision tasks such as 3D reconstruction or image detection configurable with textual, 2D image, and 3D CAD model queries.
3D-COCO is an extension of the original MS-COCO dataset providing 3D models and 2D-3D alignment annotations. We complete the existing MS-COCO dataset with 28K 3D models collected on ShapeNet and Objaverse. By using an IoU-based method, we match each MS-COCO annotation with the best 3D models to provide a 2D-3D alignment.
- Categories:
768 Views
There is growing widespread adoption of augmented reality in tech-driven industries and sectors of society, such as medicine, gaming, flight simulation, education, interior design and modelling, entertainment, construction, tourism, repair and maintenance, public safety, agriculture, and quantum computing. However, ensuring smooth and intuitive interactions with augmented objects is challenging, requiring practical performance evaluation and optimisation models to assess and improve users' experiences as they engage with AR-enhanced devices or systems.
- Categories:
109 Views
This dataset was collected from real-world recycling plants, primarily consisting of crushed glass from disassembled display devices. The dataset contains images of flat glass mixed with solid glass, colored glass, plastic film, and aluminum foil. The colored glass originated from frame areas, while the aluminum foil came from cable shielding materials. Additional objects, such as solid glass and plastic films, were sourced from other recycled materials like glass bottles and packaging.
- Categories:
159 Views
- Categories:
561 Views
CrackAirport features images containing unique elements such as aircraft, T-hangars, vegetation, airport markings and signs, as well as evidence of previous maintenance. The dataset was captured using a Sony ILCE-7RM4A camera mounted on a drone flying at an altitude of 100 feet AGL. The imagery was sourced from various local airports in Tennessee and includes common pavement distresses and environmental patterns typical of airport surfaces. The images were annotated and then cropped into 512x512 pixel segments for training.
- Categories:
781 Views
The ultrasound video data were collected from two sets of neck ultrasound videos of ten healthy subjects at the Ultrasound Department of Longhua Hospital Affiliated to Shanghai University of Traditional Chinese Medicine. Each subject included video files of two groups of LSCM, LSSCap, RSCM, and RSSCap. The video format is avi.
The MRI training data were sourced from three hospitals: Longhua Hospital, Shanghai University of Traditional Chinese Medicine; Huadong Hospital, Fudan University; and Shenzhen Traditional Chinese Medicine Hospital.
- Categories:
575 Views
These are tight pedestrian masks for the thermal images present in the KAIST Multispectral pedestrian dataset, available at https://soonminhwang.github.io/rgbt-ped-detection/
Both the thermal images themselves as well as the original annotations are a part of the parent dataset. Using the annotation files provided by the authors, we develop the binary segmentation masks for the pedestrians, using the Segment Anything Model from Meta.
- Categories:
628 Views