
Supplementary Material for IEEE-TII Transaction Article "Controller Design for Electrical Drives by Deep Reinforcement Learning - a Proof of Concept"
- Categories:
Supplementary Material for IEEE-TII Transaction Article "Controller Design for Electrical Drives by Deep Reinforcement Learning - a Proof of Concept"


Dataset for the article: "Impacts of flow alteration on Swiss floodplains observed by remote sensing".
The present data are originating from two kinds of product:
- landsat time series of surface reflectances (product of)
- discharge statistics from the Swiss Federal Office for the Environment (extracted statistics)

Collecting and analysing heterogeneous data sources from the Internet of Things (IoT) and Industrial IoT (IIoT) are essential for training and validating the fidelity of cybersecurity applications-based machine learning. However, the analysis of those data sources is still a big challenge for reducing high dimensional space and selecting important features and observations from different data sources. The study proposes a new testbed for an IIoT network that was utilised for creating new datasets called TON_IoT that collected Telemetry data, Operating systems data and Network data.
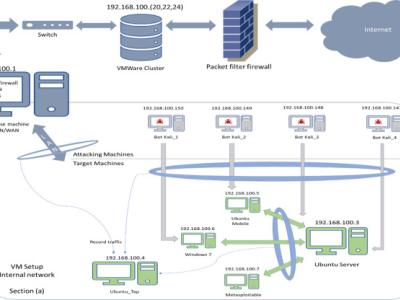
The proliferation of IoT systems, has seen them targeted by malicious third parties. To address this challenge, realistic protection and investigation countermeasures, such as network intrusion detection and network forensic systems, need to be effectively developed. For this purpose, a well-structured and representative dataset is paramount for training and validating the credibility of the systems. Although there are several network datasets, in most cases, not much information is given about the Botnet scenarios that were used.
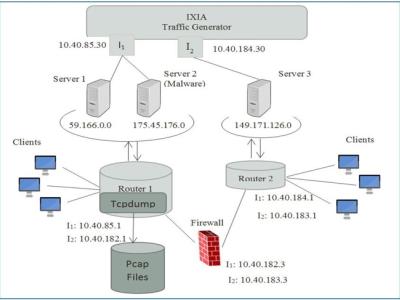
One of the major research challenges in this field is the unavailability of a comprehensive network based data set which can reflect modern network traffic scenarios, vast varieties of low footprint intrusions and depth structured information about the network traffic. Evaluating network intrusion detection systems research efforts, KDD98, KDDCUP99 and NSLKDD benchmark data sets were generated a decade ago. However, numerous current studies showed that for the current network threat environment, these data sets do not inclusively reflect network traffic and modern low footprint attacks.

The dataset consists of 60285 character image files which has been randomly divided into 54239 (90%) images as training set 6046 (10%) images as test set. The collection of data samples was carried out in two phases. The first phase consists of distributing a tabular form and asking people to write the characters five times each. Filled-in forms were collected from around 200 different individuals in the age group 12-23 years. The second phase was the collection of handwritten sheets such as answer sheets and classroom notes from students in the same age group.
FIWARE Innovation Arena ideas submitted, including text and images
The year 2018 was declared as "Turkey Tourism Year" in China. The purpose of this dataset, tourists prefer Turkey to be able to determine. The targeted audience was determined through TripAdvisor. Later, the travel histories of individuals were gathered in four different groups. These are the individuals’ travel histories to Europe (E), World (W) Countries and China (C) City/Province and all (EWC). Then, "One Zero Matrix (OZ)" and "Frequency Matrix (F)" were created for each group. Thus, the number of matrices belonging to four groups increased to eight.
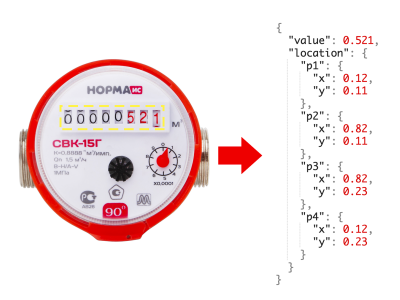
Water meter dataset. Contains 1244 water meter images. Assembled using a crowdsourcing platform Yandex.Toloka.
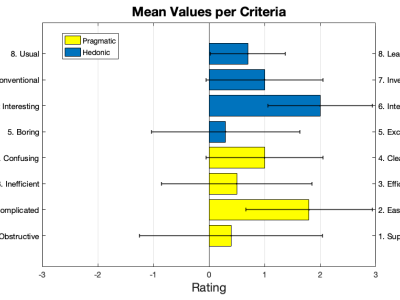
The plotted graph shows the mean values of the framework evaluation data provided by 10 participants over 8 criteria.

As one of the research directions at OLIVES Lab @ Georgia Tech, we focus on the robustness of data-driven algorithms under diverse challenging conditions where trained models can possibly be depolyed. To achieve this goal, we introduced a large-sacle (1.M images) object recognition dataset (CURE-OR) which is among the most comprehensive datasets with controlled synthetic challenging conditions. In CURE-OR dataset, there ar
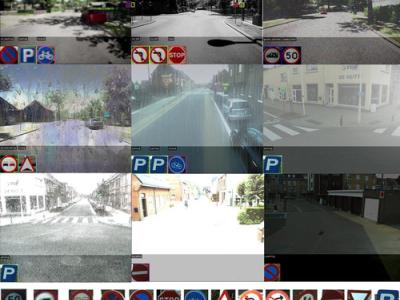
As one of the research directions at OLIVES Lab @ Georgia Tech, we focus on the robustness of data-driven algorithms under diverse challenging conditions where trained models can possibly be depolyed. To achieve this goal, we introduced a large-sacle (~1.72M frames) traffic sign detection video dataset (CURE-TSD) which is among the most comprehensive datasets with controlled synthetic challenging conditions. The video sequences in the

This data set contains 50 low resolution (640 x 360) short videos containing a variety real life activities.

This Dataset consist of 3Dmodels in Spherical harmonic coefficients andcorresponding shortcut of front view, the SH degree is 80.
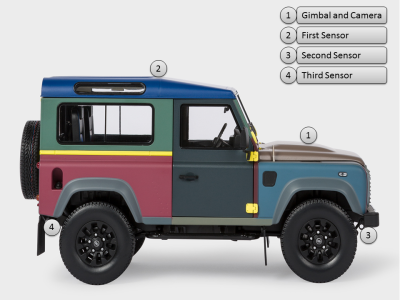
Real sampled data of a moving vehicle is provided.

Blended Learning has been widely used in current basic education as a new teaching model, and how to improve the acceptance of students in Blended Learning is a hot issue that needs to be solved in the practice of teaching.
There is a paper for the dataset:
Primary science curriculum student acceptance of blended learning: structural equation modeling and visual analytics
doi: 10.1007/s40692-021-00206-8
Full Text: https://rdcu.be/cAooZ
Abstract


The modified CASIA dataset is created for research topics like: perceptual image hash, image tampering detection, user-device physical unclonable function and so on.

As one of the research directions at OLIVES Lab @ Georgia Tech, we focus on the robustness of data-driven algorithms under diverse challenging conditions where trained models can possibly be depolyed.

The MyoUP (Myo University of Patras) database contains recordings from 8 intact subjects (3 females, 5 males; 1 left handed, 7 right handed; age 22.38 ± 1.06 years). The acquisition process was divided into three parts: 5 basic finger movements (E1), 12 isotonic and isometric hand configurations (E2), and 5 grasping hand-gestures (E3). The recording device used was the Myo Armband by Thalmic labs (8 dry sEMG channels and sampling frequency of 200Hz). The dataset was created for use in gesture recognition tasks.
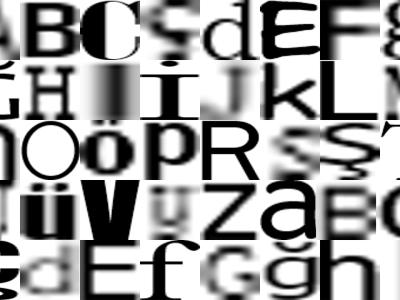
This dataset includes all letters from Turkish Alphabet in two parts. In the first part, the dataset was categorized by letters, and the second part dataset was categorized by fonts. Both parts of dataset includes the features mentioned below.
The all characters in Turkish Alphabet are included (a, b, c, ç, d, e, f, g, ğ, h, ı, i, j, k, l, m, n, o, ö, p, r, s, ş, t, u, ü, v, y, z).

Boğaziçi University DDoS dataset (BOUN DDoS) is generated in Boğaziçi University via Hping3 traffic generator software by flooding TCP SYN, and UDP packets. This dataset includes attack-free user traffic as well as attack traffic and suitable for evaluating network-based DDoS detection methods. Attacks are towards one victim server connected to the backbone router of the campus. Attack packets have randomly generated spoofed source IP addresses. The data-trace was recorded on the backbone and included over 4000 active hosts.

The Onera Satellite Change Detection dataset addresses the issue of detecting changes between satellite images from different dates.