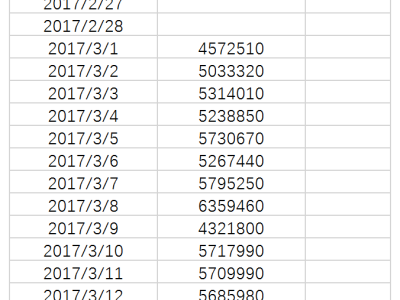
This folder contains two csv files and one .py file. One csv file contains NIST ground PV plant data imported from https://pvdata.nist.gov/. This csv file has 902 days raw data consisting PV plant POA irradiance, ambient temperature, Inverter DC current, DC voltage, AC current and AC voltage. Second csv file contains user created data. The Python file imports two csv files. The Python program executes four proposed corrupt data detection methods to detect corrupt data in NIST ground PV plant data.
- Categories: