Machine Learning

Student learning willingness is the decisive factor for achieving the final learning outcomes in curriculum teaching. On the other hand, the final learning outcomes achieved by students in the curriculum are a true reflection of student learning willingness. This paper selects 6 types of theoretical teaching method data and 4 types of student engagement behavior data used in the teaching process of the "Computer Systems" course in the Software Engineering major of Information Engineering School in the academic years 2021, 2022, and 2023 as the basic data.
- Categories:
 406 Views
406 Views
The Partial Discharge - Localisation Dataset, abbreviated: PD-Loc Dataset is an extensive collection of acoustic data specifically curated for the advancement of Partial Discharge (PD) localisation techniques within electrical machinery. Developed using a precision-engineered 32-sensor acoustic array, this dataset encompasses a wide array of signals, including chirps, white Gaussian noise, and PD signals.
- Categories:
1114 Views
To test the feasibility of the idea: Using the processed data of sentinel-2 and GlobeLand30 as the input image and ground truth of subspace clustering for land cover classification, a dataset named 'MSI_Gwadar' is created.
'MSI_Gwadar' is a multi-spectral remote sensing image of Gwadar (town and seaport, southwestern Pakistan) and its four regions of interest, which includes MATLAB data files and ground truth files of the study area and its four regions of interest.
- Categories:
312 Views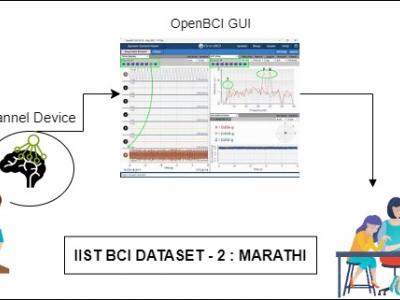
Problems of neurodegenerative disorder patients can be solved by developing Brain-Computer Interface (BCI) based solutions. This requires datasets relevant to the languages spoken by patients. For example, Marathi, a prominent language spoken by over 83 million people in India, lacks BCI datasets based on the language for research purposes. To tackle this gap, we have created a dataset comprising Electroencephalograph (EEG) signal samples of selected common Marathi words.
- Categories:
529 Views
With the goal of improving machine learning approaches in inverse scattering, we provide an experimental data set collected with a 2D near-field microwave imaging system. Machine learning approaches often train solely on synthetic data, and one of the reasons for this is that no experimentally-derived public data set exists. The imaging system consists of 24 antennas surrounding the imaging region, connected via a switch to a vector network analyzer. The data set contains over 1000 full Scattering parameter scans of five targets at numerous positions from 3-5 GHz.
- Categories:
747 Views
The results are based on the measurements conducted on small drones and a bionic bird using a 60 GHz millimeter wave radar, analyzing their micro-Doppler characteristics in both time and frequency domain. The results are presented in .pkl format. The more detailed description of the data and how the authors processed it will be updated soon.
- Categories:
1684 Views
This dataset presents real-world IoT device traffic captured under a scenario termed "Active," reflecting typical usage patterns encountered by everyday users. Our methodology emphasizes the collection of authentic data, employing rigorous testing and system evaluations to ensure fidelity to real-world conditions while minimizing noise and irrelevant capture.
- Categories:
869 Views
The rise of e-commerce in Latin America has been driven by the digital presence of the younger generations and the adaptation of retail businesses to online sales channels. The COVID-19 pandemic has further accelerated this shift, forcing businesses to enhance their online commerce strategies. Peru has witnessed a notable 131\% increase in online shoppers from 2019 to 2021. However, the absence of a unique global code for product identification negatively affects the Zero Moment of Truth (ZMOT) in customer decision-making.
- Categories:
21 Views
An AI-based Ancient Hebrew Language Translator aims to revive Ancient Hebrew by constructing a comprehensive dataset with contemporary and ancient Hebrew samples. Seamless integration of the Google Vision API facilitates Optical Character Recognition (OCR) for image processing. The translation process initiates in English through the model, leading to a multilingual interface. This initiative represents a crucial step in preserving ancient languages in the digital age.
- Categories:
12 Views
Weconsiderfivebenchmarkdatasets-Pokec-z,NBA,
- Categories:
30 Views