
Mizo or Lushai language is the official language of Mizoram, a state in the north-eastern part of India. It is an under-resourced language that falls under the Tibeto-Burman language family and is highly tonal in nature.
- Categories:
Mizo or Lushai language is the official language of Mizoram, a state in the north-eastern part of India. It is an under-resourced language that falls under the Tibeto-Burman language family and is highly tonal in nature.
This paper presents a real-time reconfigurable Cyber-Power Grid Operation Testbed (CPGrid-OT) with multi-vendor, industry-grade hardware, and software.
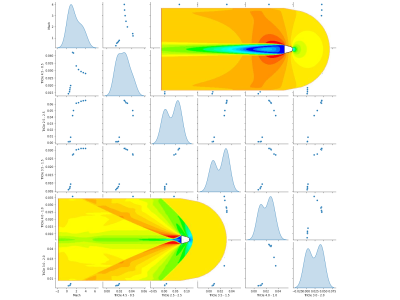
The rocket nose-cone shapes have been generated by blending few conic sections together (two conic sections in one) and the simulated against mach number regime from subsonic through transonic to supersonic. The aerodynamic drag coefficients have been recoded for each shape for each mach number.

The ability to perceive human facial emotions is an essential feature of various multi-modal applications, especially in the intelligent human-computer interaction (HCI) area. In recent decades, considerable efforts have been put into researching automatic facial emotion recognition (FER). However, most of the existing FER methods only focus on either basic emotions such as the seven/eight categories (e.g., happiness, anger and surprise) or abstract dimensions (valence, arousal, etc.), while neglecting the fruitful nature of emotion statements.
The dataset analyzed in this study is the result of a systematic literature review and a crowdsourced mini-project that aimed to identify and validate metrics relevant to maternal and neonatal healthcare examinations. The study involved a diverse group of participants, including 193 registered medical personnel from reputable institutions and 161 non-medical individuals who were active on various social media platforms related to maternal and neonatal healthcare.
Motion analysis forms a very important research topic with a general mathematical background and applications in different areas including engineering, robotics, and neurology. This paper presents the use of the global navigation satellite system (GNSS) for detection and recording of the moving body position and the simultaneous acquisition of signals from further sensors. The application is related to monitoring of physical activity and the use of wearable sensors of the heart rate and acceleration during different motion patterns.

The Hook-Jeeves algorithm is a direct search algorithm that is widely used for multi-parameter optimisation problems in engineering computation. The file code provided contains Hook-Jeeves algorithm functions and simple test cases that can be used by copying the code into Matlab.
Scenarios 1, 3, and 4 are used for the stealthy attack situation, Scenarios 2, 5, 6, and 7 are used for the target-near-islands-and-reefs situation, and Scenario 8 is used for algorithms comparison.
we propose an improved knowledge representation learning model Cluster TransD and a recommendation model Cluster TransD-GAT based on knowledge graph and graph attention networks, where the Cluster TransD model reduces the number of entity projections, makes the association between entity representations, reduces the computational pressure, and makes it better to be applied to the large knowledge graph, and the Cluster TransD-GAT model can capture the attention of different users to different relationships of items.

Gestational diabetes is a type of high blood sugar that develops during pregnancy. It can occur at any stage of pregnancy and cause problems for both the mother and the baby, during and after birth. The risks can be reduced if they are early detected and managed, especially in areas where only periodic tests of pregnant women are available. Intelligent systems designed by machine learning algorithms are remodelling all fields of our lives, including the healthcare system. This study proposes a combined prediction model to diagnose gestational diabetes.