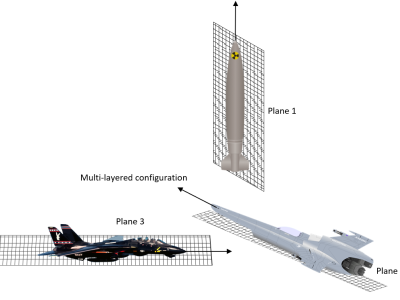
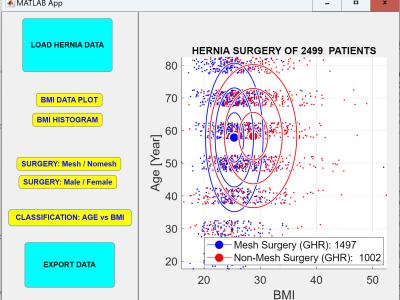
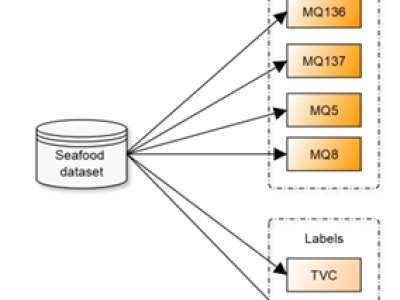
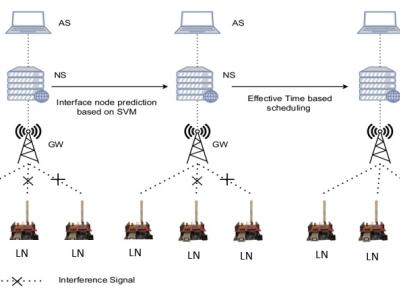
Most plant diseases have observable symptoms, and the widely used approach to detect plant leaf disease is by visually examining the affected plant leaves. A model which might carry out the feature extraction without any errors will process the classification task successfully. The technology currently faces certain limitations such as a large parameter count, slow detection speed, and inadequate performance in detecting small dense spots. These factors restrict the practical applications of the technology in the field of agriculture.
- Categories: