Machine Learning

This is the First Arabic voice Commands Dataset to provide personalized control of devices at smart homes for elder persons and persons with disabilities. The dataset contains 12 speakers, each saying 36 different phrases or words in Arabic language. The goal of this dataset is to use it in an Arabic smart home system to control home devices through voice. Participants were asked to say each phrase multiple times. The phrases to record were presented in a random order.
- Categories:
 873 Views
873 Views
The proliferation of efficient edge computing has enabled a paradigm shift of how we monitor and interpret urban air quality. Coupled with the dense spatiotemporal resolution realized from large-scale wireless sensor networks, we can achieve highly accurate realtime local inference of airborne pollutants. In this paper, we introduce a novel Deep Neural Network architecture targeted at latent time-series regression tasks from continuous, exogenous sensor measurements, based on the Transformer encoder scheme and designed for deployment on low-cost power-efficient edge processors.
- Categories:
1273 Views
This is a protein negative interaction dataset, generated by our proposed method the “Features Dissimilarity-based Negative Generation” approach to generate protein negative sampling based on sequence data. It measures similarity of sequence characteristics without alignment based on Protein similarity. It achieved results of 97% compared to randomly generated negative dataset.
- Categories:
632 Views
The dataset represents the input data on which the article Bayesian CNN-BiLSTM and Vine-GMCM Based Probabilistic Forecasting of Hour-Ahead Wind Farm Power Outputs, is based. The data consist of a two-year hourly time series of measured wind speed and direction, air density, and production of two wind farms (WTs) in Croatia (Bruška and Jelinak). In addition to the two listed WTs, measurements of two nearby WTs (Glunca and Zelengrad) are also attached in training files (these WPPs are not directly analyzed in the article).
- Categories:
1683 Views
This dataset maps mood to information about the events that influenced the mood. The dataset was obtained using a web-based data collection interface developed by us. The dataset consists of 5245 days of data from 134 participants in the experiment.
- Categories:
794 Views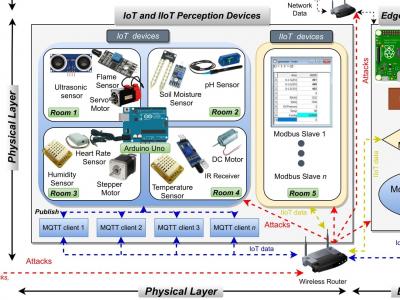
In this project, we propose a new comprehensive realistic cyber security dataset of IoT and IIoT applications, called Edge-IIoTset, which can be used by machine learning-based intrusion detection systems in two different modes, namely, centralized and federated learning. Specifically, the proposed testbed is organized into seven layers, including, Cloud Computing Layer, Network Functions Virtualization Layer, Blockchain Network Layer, Fog Computing Layer, Software-Defined Networking Layer, Edge Computing Layer, and IoT and IIoT Perception Layer.
- Categories:
24159 Views

This dataset has been employed in the following articles:
https://ieeexplore.ieee.org/document/9682692
https://ieeexplore.ieee.org/document/9871051
https://content.iospress.com/articles/technology-and-health-care/thc202198
- Categories:
470 Views
The millimeter-wave radar has the ability to sense the subtle movement of hand. However, the traditional hand gesture recognition methods are not robust in the scenario with dynamic interference. To address this issue, a robust hand gesture recognition method is proposed based on the self-attention time-series neural networks. Firstly, the original radar echo is constructed in terms of frame, sequence and channel at the input terminal of network.
- Categories:
456 Views
The measurement and diagnosis of the severity of failures in rotating machines allow the execution of predictive maintenance actions on equipment. These actions make it possible to monitor the operating parameters of the machine and to perform the prediction of failures, thus avoiding production losses, severe damage to the equipment, and safeguarding the integrity of the equipment operators. This paper describes the construction of a dataset composed of vibration signals of a rotating machine.
- Categories:
2788 Views