Supervised Learning

Please cite the following paper when using this dataset:
Vanessa Su and Nirmalya Thakur, “COVID-19 on YouTube: A Data-Driven Analysis of Sentiment, Toxicity, and Content Recommendations”, Proceedings of the IEEE 15th Annual Computing and Communication Workshop and Conference 2025, Las Vegas, USA, Jan 06-08, 2025 (Paper accepted for publication, Preprint: https://arxiv.org/abs/2412.17180).
Abstract:
- Categories:
 156 Views
156 Views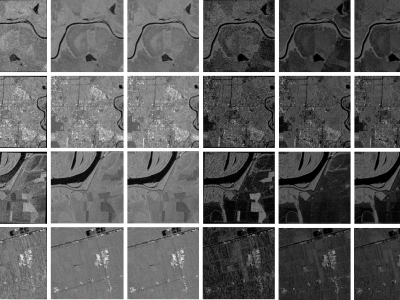
When training supervised deep learning models for despeckling SAR images, it is necessary to have a labeled dataset with pairs of images to be able to assess the quality of the filtering process. These pairs of images must be noisy and ground truth. The noisy images contain the speckle generated during the backscatter of the microwave signal, while the ground truth is generated through multitemporal fusion operations. In this paper, two operations are performed: mean and median.
- Categories:
761 Views
To download this dataset without purchasing an IEEE Dataport subscription, please visit: https://zenodo.org/records/13896353
Please cite the following paper when using this dataset:
- Categories:
1066 Views
To download the dataset without purchasing an IEEE Dataport subscription, please visit: https://zenodo.org/records/13738598
Please cite the following paper when using this dataset:
- Categories:
1361 Views
The training data consists of data from various faults from five individual configurations, while the testing data is blind and is from one individual configuration of the rock drill. A final validation data set will be from two individual configurations from the rock drill and the labels are blind.
The training data set contains data from 11 different fault classification categories, in which 10 are different failure modes and one class is from the healthy/no fault condition.
Each file follows the naming convention of data_{sensor}{individual impact cycle number}.csv.
- Categories:
148 Views
A commonly used definition of spatial disorientation (SD) in aviation is "an erroneous sense of one’s position and motion relative to the plane of the earth’s surface". There exists a wide range of SD use-cases dictated by situational factors, therefore SD has been predominantly studied using reduced motion detection experimental contexts in isolation. The study of SD by use-case makes it difficult to understand general SD occurrence and thus provide viable solutions. To investigate SD in a generalized manner, a two-part Human Activity Recognition (HAR) study was performed.
- Categories:
347 Views
The design and implementation of an anthropomorphic robotic hand control system for the Bioengineering and Neuroimaging Laboratory LNB of the ESPOL were elaborated. The myoelectric signals were obtained using a bioelectric data acquisition board (CYTON BOARD) using six channels out of 8 available, which had an amplitude of 200 [uV] at a sampling frequency of 250 [Hz].
- Categories:
2296 Views
This dataset consists of the training and the evaluation datasets for the LiDAR-based maritime environment perception presented in our journal publication "Maritime Environment Perception based on Deep Learning." Within the datasets, LiDAR raw data are processed using Deep Neural Networks (DNN). In the training dataset, we introduce the method for generating training data in Gazebo simulation. In the evaluation datasets, we provide the real-world tests conducted by two research vessels, respectively.
- Categories:
1796 Views
Visible Light Positioning is an indoor localization technology that uses wireless transmission of visible light signals to obtain a location estimate of a mobile receiver.
This dataset can be used to validate supervised machine learning approaches in the context of Received Signal Strength Based Visible Light Positioning.
The set is acquired in an experimental setup that consists of 4 LED transmitter beacons and a photodiode as receiving element that can move in 2D.
- Categories:
1132 Views
A paradigm dataset is constantly required for any characterization framework. As far as we could possibly know, no paradigmdataset exists for manually written characters of Telugu Aksharaalu content in open space until now. Telugu content (Telugu: తెలుగు లిపి, romanized: Telugu lipi), an abugida from the Brahmic group of contents, is utilized to compose the Telugu language, a Dravidian language spoken in the India of Andhra Pradesh and Telangana just a few other neighboring states. The Telugu content is generally utilized for composing Sanskrit writings.
- Categories:
18140 Views