Telugu Handwritten Vowels
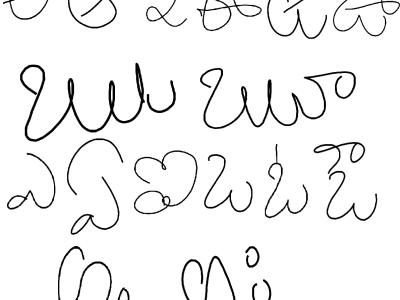
- Citation Author(s):
-
Naresh Babu Muppalaneni (National Institute of Technology Silchar, India)Prathima Chilukuri (Sree Vidyanikethan Engineering College, Tirupathi, India)D R Kumar Raja (Sree Vidyanikethan Engineering College, Tirupathi, India)
- Submitted by:
- Naresh Muppalaneni
- Last updated:
- DOI:
- 10.21227/hrkp-ba24
- Data Format:
 18186 views
18186 views
- Categories:
- Keywords:
Abstract
A paradigm dataset is constantly required for any characterization framework. As far as we could possibly know, no paradigmdataset exists for manually written characters of Telugu Aksharaalu content in open space until now. Telugu content (Telugu: తెలుగు లిపి, romanized: Telugu lipi), an abugida from the Brahmic group of contents, is utilized to compose the Telugu language, a Dravidian language spoken in the India of Andhra Pradesh and Telangana just a few other neighboring states. The Telugu content is generally utilized for composing Sanskrit writings. It was noticeable during the Eastern Chalukyas likewise known as Vengi Chalukya period. It is similar to the Kannada content, as it has developed from Kadamba and Bhattiprolu contents of the Brahmi family. Both Adikavi Pampa of Kannada and Adikavi Nannayya of Telugu hail from families local to the Vengi area.Telugu has 56 Characters (Aksharamulu) including vowels (Achchulu) and consonants (Hallulu). But, Nowadays, It seems to 52 letters (Aksharalu). In the 52 characters vowels (Acchulu) 16 and consonants (Hallulu) 36. In this work, we present a transcribed Telugu character dataset of (Acchulu) 16 characters which comprises of 1116 information tests which were gathered from a various group of peoples hand written characters with various age gatherings (from 8 years to 36 years), sexual orientations, instructive foundations, occupations, networks from three unique areas of Andhra Pradesh, India (South Region), during autumn 2019. Every individual was approached to record all the Telugu characters on paint mobile app which was been developed for capturing the images in .jpg format. The captured letters are cropped to fit the letter only and afterward each character is physically portioned from the filtered pictures. This dataset comprises of divided examined pictures of transcribed Telugu characters (Achulu) of variation sizes in .jpeg according to the telugu characters.
Convolutional Neural Network (CNN) is a deep learning approach for applying to many classification problems. In CNN, features of images can be identified automatically.We have created a Dataset for Telugu Handwritten Characters. It is difficult to recognize Telugu Handwritten Characters since each character is having many curves.
Dataset consists of 1116, Train:875 Test: 241
Instructions:
All the images are not in the same size. Since the images are captured using the Android App and later cropped to fit the character. Labels are listed in attached word document.
అ- 0
ఆ - 1
ఇ - 2
ఈ - 3
ఉ - 4
ఊ - 5
ఋ - 6
ౠ - 7
ఎ - 8
ఏ - 9
ఐ - 10
ఒ - 11
ఓ - 12
ఔ - 13
అం - 14
అః - 15


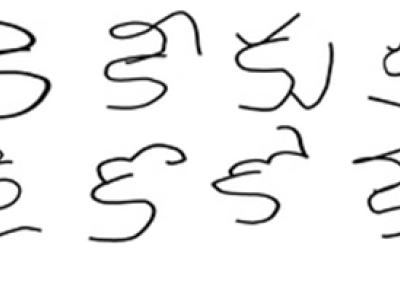



Dataset consists of 1116, Train:875 Test: 241