Computer Vision

This dataset, referred to as LIED (Light Interference Event Dataset), is showcased in the article titled 'Identifying Light Interference in Event-Based Vision'. We proposed the LIED, it has three categories of light interference, including strobe light sources, non-strobe light sources and scattered or reflected light. Moreover, to make the datasets contain more realistic scenarios, the datasets include the dynamic objects and the situation of camera static and the camera moving. LIED was recorded by the DAVIS346 sensor. It provides both frame and events with the resolution of 346 * 260.
- Categories:
 84 Views
84 Views
The dataset comprises a diverse collection of images featuring windows alongside various artificial light sources, such as bulbs, LEDs, and tube lights. Each image captures the interplay of natural and artificial illumination, offering a rich visual spectrum that encompasses different lighting scenarios. This compilation is invaluable for applications ranging from architectural design and interior decor to computer vision and image processing.
- Categories:
106 Views
Investigating how people perceive virtual reality videos in the wild (i.e., those captured by everyday users) is a crucial and challenging task in VR-related applications due to complex authentic distortions localized in space and time. Existing panoramic video databases only consider synthetic distortions, assume fixed viewing conditions, and are limited in size. To overcome these shortcomings, we construct the VR Video Quality in the Wild (VRVQW) database, which is one of the first of its kind, and contains 502 user-generated videos with diverse content and distortion characteristics.
- Categories:
106 Views
STP dataset is a dataset for Arabic text detection on traffic panels in the wild. It was collected from Tunisia in “Sfax” city, the second largest Tunisian city after the capital. A total of 506 images were gathered through manual collection one by one, with each image energizing Arabic text detection challenges in natural scene images according to real existing complexity of 15 different routes in addition to ring roads, roundabouts, intersections, airport and highways.
- Categories:
230 Views
Deficient domestic wastewater management, industrial waste, and floating debris are some leading factors that contribute to inland water pollution. The surplus of minerals and nutrients in overly contaminated zones can lead to the invasion of different invasive weeds. Lemnaceae, commonly known as duckweed, is a family of floating plants that has no leaves or stems and forms dense colonies with a fast growth rate. If not controlled, duckweed establishes a green layer on the surface and depletes fish and other organisms of oxygen and sunlight.
- Categories:
149 Views
FaceEngine is a face recognition database for using in CCTV based video surveillance systems. This dataset contains high-resolution face images of around 500 celebrities. It also contains images captured by the CCTV camera. Against each person folder, there are more than 10 images for that person. Face features can be extracted from this database. Also, there are test videos in the dataset that can be used to test the system. Each unique ID contains high resolution images that might help CCTV surveillance system test or training face detection model.
- Categories:
821 Views
Low-light images and video footage often exhibit issues due to the interplay of various parameters such as aperture, shutter speed, and ISO settings. These interactions can lead to distortions, especially in extreme lighting conditions. This distortion is primarily caused by the inverse relationship between decreasing light intensity and increasing photon noise, which gets amplified with higher sensor gain. Additionally, secondary characteristics like white balance and color effects can also be adversely affected and may require post-processing correction.
- Categories:
2121 Views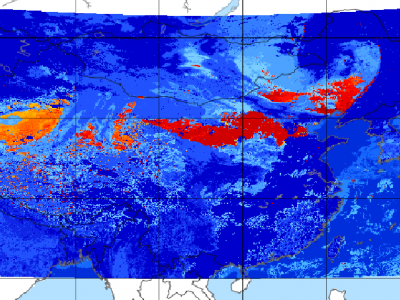
Since meteorological satellites can observe the Earth’s atmosphere from a spatial perspective at a large scale, in this paper, a dust storm database is constructed using multi-channel and dust label data from the Fengyun-4A (FY-4A) geosynchronous orbiting satellite, namely, the Large-Scale Dust Storm database based on Satellite Images and Meteorological Reanalysis data (LSDSSIMR), with a temporal resolution of 15 minutes and a spatial resolution of 4 km from March to May of each year during 2020–2022.
- Categories:
762 Views
The Numerical Latin Letters (DNLL) dataset consists of Latin numeric letters organized into 26 distinct letter classes, corresponding to the Latin alphabet. Each class within this dataset encompasses multiple letter forms, resulting in a diverse and extensive collection. These letters vary in color, size, writing style, thickness, background, orientation, luminosity, and other attributes, making the dataset highly comprehensive and rich.
- Categories:
494 Views
Our video action dataset is generated using a 3D simulation program developed in Unity. Each data sample consists of a video capturing a human performing various actions. Our initial set of actions comprises a total of 10 different yoga poses: camel, chair, child's pose, lord of the dance, lotus, thunderbolt, triangle, upward dog, warrior II, and warrior III. Within each of these 10 yoga poses, there are four variations, some exhibiting more pronounced differences than others. This results in a total of 40 action types within our dataset.
- Categories:
113 Views