Computer Vision

Quantifying performance of methods for tracking and mapping tissue in endoscopic environments is essential for enabling image guidance and automation of medical interventions and surgery. Datasets developed so far either use rigid environments, visible markers, or require annotators to label salient points in videos after collection. These are respectively: not general, visible to algorithms, or costly and error-prone. We introduce a novel labeling methodology along with a dataset that uses said methodology, Surgical Tattoos in Infrared (STIR).
- Categories:
 2059 Views
2059 Views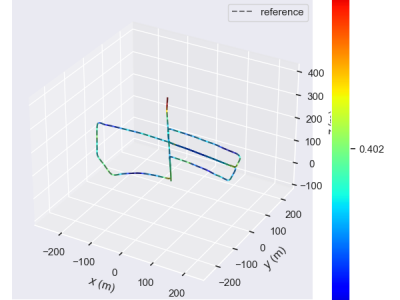
This dataset was used to support our work and provided to the review for reference.
- Categories:
101 Views
This is a PART of the dataset used in our paper titled "Detecting Anomalous Robot Motion in Collaborative Robotic Manufacturing Systems".
- Categories:
34 Views
This is a PART of the dataset used in our paper titled "Detecting Anomalous Robot Motion in Collaborative Robotic Manufacturing Systems".
- Categories:
44 Views
Recognizing and categorizing banknotes is a crucial task, especially for individuals with visual impairments. It plays a vital role in assisting them with everyday financial transactions, such as making purchases or accessing their workplaces or educational institutions. The primary objectives for creating this dataset were as follows:
- Categories:
319 Views
This dataset contains video-clips of five volunteers developing daily life activities. Each video-clip is recorded with a Far InfraRed (FIR) camera and includes an associated file which contains the three-dimensional and two-dimensional coordinates of the main body joints in each frame of the clip. This way, it is possible to train human pose estimation networks using FIR imagery.
- Categories:
448 Views
To treat visual attention defficiency and train pulmonary function simulataneously, we developed new Virtual reality(VR) system. Proposed VR system is consisted of three VR training games(Rocket game, Candle game and Food game).
We conducted user study on 24 ADHD children and collected Pulmonary function test(PFT), Advanced test of attention(ATA).
In this file, we coded data into the form that can be used SPSS statstic tool.
We wanted to compare date in two ways, pre-post comparision and between-subjects comparision.
- Categories:
45 Views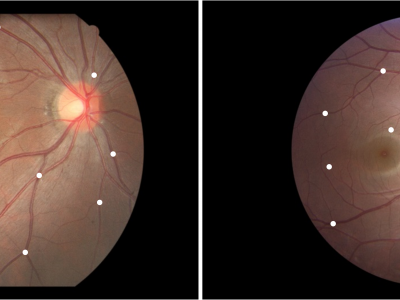
Fundus Image Myopia Development (FIMD) dataset contains 70 retinal image pairs, in which, there is obvious myopia development between each pair of images. In addition, each pair of retinal images has a large overlap area, and there is no other retinopathy. In order to perform a reliable quantitative evaluation of registration results, we follow the annotation method of Fundus Image Registration (FIRE) dataset [1] to label control points between the pair of retinal images with the help of experienced ophthalmologists. Each image pair is labeled with
- Categories:
271 Views
SYPHAXAR dataset is a dataset for Arabic text detection in the wild. It was collected from Tunisia in “Sfax” city, the second largest Tunisian city after the capital. A total of 3078 images were gathered through manual collection one by one, with each image energizing text detection challenges in nature according to real existing complexity of 15 different routes along with ring roads, intersections and roundabouts. These annotated images consist of more than 31000 objects, each of which is enclosed within a bounding box.
- Categories:
242 Views
It is important to accurately classify the defects in hot rolled steel strip since the detection of defects in hot rolled steel strip is closely related to the quality of the fifinal product. The lack of actual hot-rolled strip defect data sets currently limits further research on the classifification of hot-rolled strip defects to some extent. In real production, the convolutional neural network (CNN)-based algorithm has some diffificulties, for example, the algorithm is not particularly accurate in classifying some uncommon defects.
- Categories:
526 Views