Machine Learning

The Metaverse Gait Authentication Dataset (MGAD) is a large-scale gait dataset designed for biometric authentication in virtual environments.
- Categories:
 243 Views
243 Views
We curated and release a real-world medical clinical dataset, namely MedCD, in the context of building generative artificial intelligence (AI) applications in the clinical setting. The MedCD dataset is one of the accomplishments from our longitudinal applied AI research and deployment in a tertiary care hospital in China. First, the dataset is real and comprehensive, in that it was sourced from real-world electronic health records (EHRs), clinical notes, lab examination reports and more.
- Categories:
239 Views
The data set is a time series of gas concentration collected continuously in a coal mine in China. The data set collects data once every hour. The gas concentration record period in this data set is from 0 : 00 on January 1,2021 to 15 : 00 on March 27,2021. The data set only contains two attributes : time and gas concentration on the working face.
- Categories:
74 Views
One of the leading causes of early health detriment is the increasing levels of air pollution in major cities and eventually in indoor spaces. Monitoring the air quality effectively in closed spaces like educational institutes and hospitals can improve both the health and the life quality of the occupants. In this paper, we propose an efficient Indoor Air Quality (IAQ) monitoring and management system, which uses a combination of cutting-edge technologies to monitor and predict major air pollutants like CO2, PM2.5, TVOCs, and other factors like temperature and humidity.
- Categories:
373 Views
A new small aerial flame dataset, called the Aerial Fire and Smoke Essential (AFSE) dataset, is created which is comprised of screenshots from different YouTube wildfire videos as well as images from FLAME2. Two object categories are included in this dataset: smoke and fire. The collection of images is made to mostly contain pictures utilizing aerial viewpoints. It contains a total of 282 images with no augmentations and has a combination of images with only smoke, fire and smoke, and no fire nor smoke.
- Categories:
768 Views
The Explainable Sentiment Analysis Dataset provides annotated sentiment classification data for Amazon Reviews and IMDB Movie Reviews, facilitating the evaluation of sentiment analysis models with a focus on explainability. It includes ground-truth sentiment labels, model-generated predictions, and fine-grained classification results obtained from various large language models (LLMs), including both proprietary (GPT-4o/GPT-4o-mini) and open-source models (DeepSeek-R1 full and distilled models).
- Categories:
180 Views
The TripAdvisor online airline review dataset, spanning from 2016 to 2023, provides a comprehensive collection of passenger feedback on airline services during the COVID-19 pandemic. This dataset includes user-generated reviews that capture sentiments, preferences, and concerns, allowing for an in-depth analysis of shifting customer priorities in response to pandemic-related disruptions. By examining these reviews, the dataset facilitates the study of evolving passenger expectations, changes in service perceptions, and the airline industry's adaptive strategies.
- Categories:
241 Views
DALHOUSIE NIMS LAB ATTACK IOT DATASET 2025-1 dataset comprises of four prevalent types attacks, namely Portscan, Slowloris, Synflood, and Vulnerability Scan, on nine distinct Internet of Things (IoT) devices. These attacks are very common on the IoT eco-systems because they often serve as precursors to more sophisticated attack vectors. By analyzing attack vector traffic characteristics and IoT device responses, our dataset will aid to shed light on IoT eco-system vulnerabilities.
- Categories:
346 Views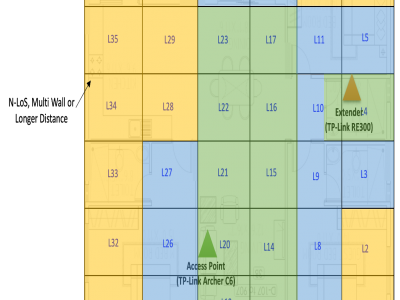
This dataset supports the BWiFi framework, an intelligent method to identify optimal Wi-Fi zones in mesh networks. The home dataset, collected over one month across 36 zones, and the office dataset, collected over two months across 40 zones, systematically measure Wi-Fi quality and application performance metrics. Using clustering techniques and heuristic analysis, BWiFi evaluates zone performance to recommend optimal connectivity areas.
- Categories:
565 Views
This dataset includes spectra of 250 corn samples with different vitality levels, with a data size of 250*256, categorized into five vitality grades. The imaging spectrometer employs a series spectrophotometer, model N17E, with a spectral range of 874-1734nm and a spectral resolution of 5nm. The CCD used is model ICL-B1410, featuring 1600×1200 pixels, and is equipped with an OLES22 lens with a focal length of 22mm.
- Categories:
127 Views