Image Processing

A new small aerial flame dataset, called the Aerial Fire and Smoke Essential (AFSE) dataset, is created which is comprised of screenshots from different YouTube wildfire videos as well as images from FLAME2. Two object categories are included in this dataset: smoke and fire. The collection of images is made to mostly contain pictures utilizing aerial viewpoints. It contains a total of 282 images with no augmentations and has a combination of images with only smoke, fire and smoke, and no fire nor smoke.
- Categories:
 724 Views
724 Views
The Ancient Handwritten Devanagari Documents dataset is a curated collection of historical manuscripts written in the Devanagari script. It comprises digitized images of handwritten texts from various periods, containing diverse calligraphic styles, degradations, and linguistic variations. This dataset is designed for research in optical character recognition (OCR), handwritten text recognition (HTR), word spotting in historical documents and linguistic analysis.
- Categories:
91 Views
Augmented reality (AR) is a rapidly evolving field, yet research has predominantly focused on indoor applications, leaving outdoor environments relatively underexplored. Metric Depth Estimation (MDE) plays a pivotal role in AR, enabling essential functionalities such as object placement and occlusion handling by extracting depth and perspective information from single 2D images.
- Categories:
229 Views
This dataset comprises 33,800 images of underwater signals captured in aquatic environments. Each signal is presented against three types of backgrounds: pool, marine, and plain white. Additionally, the dataset includes three water tones: clear, blue, and green. A total of 12 different signals are included, each available in all six possible background-tone combinations.
- Categories:
465 Views
The dataset consists of aerial images captured using a UAV (Unmanned Aerial Vehicle) along with metadata detailing the camera's position, orientation, and settings during the image acquisition process. This dataset was created for the purpose of evaluating algorithms for matching camera images to satellite images. Each data entry includes:
- Categories:
502 Views
This dataset contains high-resolution retinal fundus images collected from 495 unique subjects from Eye Care hospital in Aizawl, Mizoram, for diabetic retinopathy (DR) detection and classification. The images were captured over five years using the OCT RS 330 device, which features a 45° field of view (33° for small-pupil imaging), a focal length of 45.7 mm, and a 6.25 mm sensor width. Each image was acquired at a resolution of 3000x3000 pixels, ensuring high diagnostic quality and the visibility of subtle features like microaneurysms, exudates, and hemorrhages.
- Categories:
784 Views
Facility agriculture and arable land data play crucial roles in modern agricultural management and sustainable development. Accurate and up-to-date information regarding facility agriculture, including greenhouses, hydroponic systems, and other controlled environments, enables farmers and policymakers to make informed decisions. It helps in optimizing resource use, improving crop yields, and ensuring food security. Meanwhile, arable land data are essential for monitoring and managing the availability and quality of land suitable for cultivation.
- Categories:
87 Views
The proper evaluation of food freshness is critical to ensure safety, quality along with customer satisfaction in the food industry. While numerous datasets exists for individual food items,a unified and comprehensive dataset which encompass diversified food categories remained as a significant gap in research. This research presented UC-FCD, a novel dataset designed to address this gap.
- Categories:
371 Views
Brain tumors are among the most severe and life-threatening conditions affecting both children and adults. They constitute approximately 85-90% of all primary Central Nervous System (CNS) tumors, with an estimated 11,700 new cases diagnosed annually. The 5-year survival rate for individuals with malignant brain or CNS tumors is alarmingly low, at 34% for men and 36% for women. Brain tumors are categorized into various types, including benign, malignant, and pituitary tumors.
- Categories:
518 Views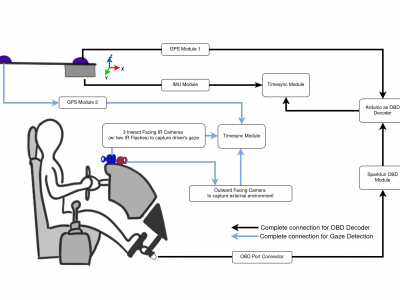
Repeated Route Naturalistic Driving Dataset (R2ND2) is a dual-perspective dataset for driver behavior analysis constituent of vehicular data collected using task-specific CAN decoding sensors using OBD port and external sensors, and (b) gaze-measurements collected using industry-standard multi-camera gaze calibration and collection system. Our experiment is designed to consider the variability associated with driving experience that depends on the time of day and provides valuable insights into the correlation of these additional metrics on driver behavior.
- Categories:
446 Views