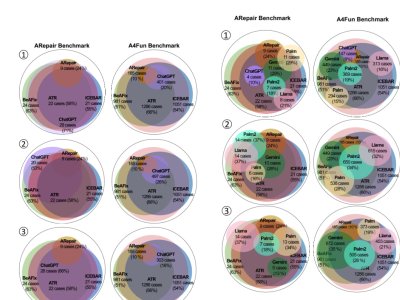
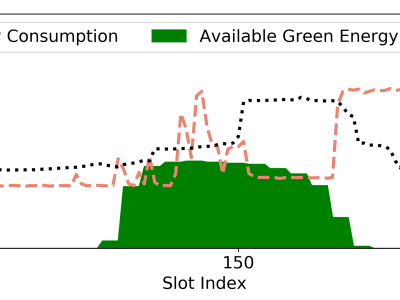
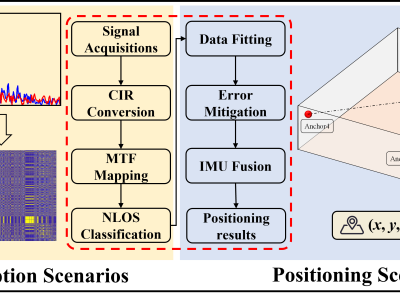
<p class="MsoNormal"><span style="mso-spacerun: 'yes'; font-family: 宋体; mso-ascii-font-family: Calibri; mso-hansi-font-family: Calibri; mso-bidi-font-family: 'Times New Roman'; font-size: 10.5000pt; mso-font-kerning: 1.0000pt;"><span style="font-family: Calibri;">This dataset contains expert evaluations of various text features using Grey Relational Analysis (GRA), comparing the performance of original and new prompt words.
- Categories: