Bluff Body Shape Optimization of Vortex Flowmeters Based on Computational Fluid Dynamics and Convolutional Neural Networks
- Citation Author(s):
-
Yingbin He (Shandong University)
- Submitted by:
- Yingbin He
- Last updated:
- DOI:
- 10.21227/k3h4-p450
 152 views
152 views
- Categories:
- Keywords:
Abstract
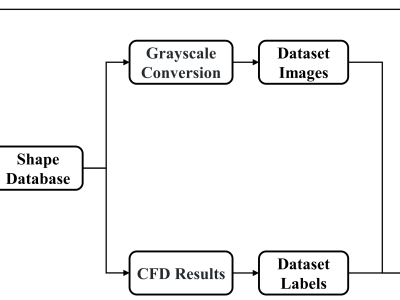
This dataset provides a comprehensive collection of various resources, including the results from Computational Fluid Dynamics (CFD) simulations, the associated CFD processing code, and the dataset along with the source code used for training Convolutional Neural Networks (CNNs). Additionally, it includes data generated by genetic algorithms and the corresponding source code for implementing these algorithms. These resources serve as a complete reference for researchers and practitioners looking to explore or reproduce the experiments, as they cover the full workflow from data generation to algorithm implementation, including the computational tools used throughout. This dataset is designed to support further research, development, and optimization in fields involving CFD, machine learning, and genetic algorithms.
Instructions:
Image Dataset Generation:
Generating Images Based on Given Parameters:
File: gen_picture.py, Method: Latin Hypercube Sampling (LHS)
Objective: The script generates images based on a set of parameters sampled using the Latin Hypercube Sampling (LHS) method. This method helps in generating a distribution of parameter combinations for the image generation process. The images are saved in an image folder.
Parameter Distribution Visualization:
File: visualize.py
Objective: This script visualizes the distribution of the parameters that were used in the image generation process. It helps to understand how the sampled parameters are spread across the specified ranges.
Label Dataset:
Data Extraction from ANSYS Parameterized Simulation Files:
File: special_finding.py
Objective: This script extracts specific data from ANSYS parameterized simulation files, which contain results based on different input parameters.
Data Integrity Check:
File: scan.py
Objective: After extracting the data, this script ensures its integrity. It checks whether the extracted data is complete and consistent, ensuring there are no missing or corrupted values.
Statistical Data Extraction:
File: data_cal.py
Objective: This script performs statistical analysis on the extracted data and computes specific metrics, which are then saved to findresults.csv. The output data includes key statistical insights from the simulations.
Data Preprocessing for Label Files:
Objective: Once the data is extracted and processed, the first two columns of the dataset are removed. Then, the floating-point numbers in the dataset are rounded to two decimal places. Additionally, values less than 0.1 or negative values are replaced with zero, making the dataset suitable for use as a label dataset.






