RetinaX dataset
- Citation Author(s):
-
Jiacheng Yang (Fudan University)
- Submitted by:
- jiacheng yang
- Last updated:
- DOI:
- 10.21227/ckdf-ak90
 205 views
205 views
- Categories:
- Keywords:
Abstract
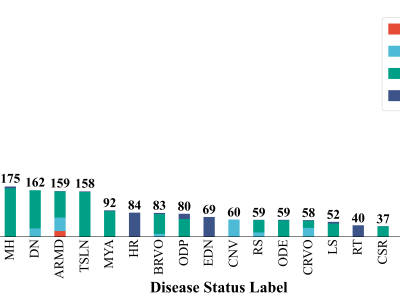
RetinaX dataset is built by selectively combining four publicly available datasets: the STARE dataset, ARIA dataset, RFMiD dataset, and RFMiD 2.0 dataset. It contains a total of 2,514 images and 24 distinct labels, covering nearly all common and rare retinal diseases. The label distribution and sample count are shown in the above figure, following a long-tail pattern, and includeing a wide range of disease status: DR (Diabetic Retinopathy), ODC (Optic Disc Cupping), MH (Media Haze), DN (Drusen), ARMD (Age-Related Macular Degen-eration), TSLN (Tessellation), MYA (Myopia), HR (Hemorrhagic Retinopathy), BRVO (Branch Retinal Vein Occlusion), ODP (Optic Disc Pallor), EDN (Ectopic Detachment), CNV (Choroidal Neovascularization), RS (Retinitis), ODE (Optic Disc Edema), CRVO (Central Reti-nal Vein Occlusion), LS (Laser Scars), RT (Retinal Traction), CSR (Central Serous Retinopathy), CME (Cystoid Macular Edema), ASR (Arteriosclerotic Retinopathy), CRS (Chorioreti-nitis), CWS (Cotton Wool Spots), CRAO (Cilioretinal Artery Occlusion). The "Normal" class has the most samples (754), while CRAO has the fewest (10), with an imbalance ratio of 75.
Instructions:
The training and test sets for each class are split in a ratio close to 4:1, and there is a certain degree of domain shift between them since the images vary in quality. The image indices and labels for the training and test sets are available at train_data.csv and test_data.csv.






