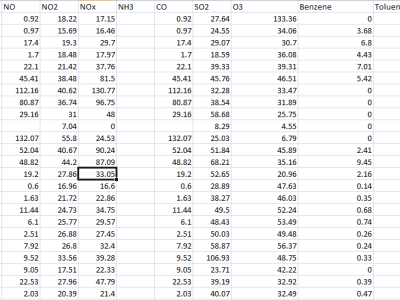
This dataset was curated mainly to cater to mitigation strategies for the Human-Peafowl Conflict that exists in these regions. The absence of natural predators has contributed to a significant increase in the peafowl population, exacerbating challenges for farmers. Peafowls are sometimes considered agricultural pests due to their tendency to feed on and damage crops. The vocalizations are from the Indian Peafowl (Pavo cristatus), a species native to the Indian subcontinent and especially abundant in India and Sri Lanka.
- Categories: