Machine Learning

Clean energy technologies, encompassing renewable resources like solar, wind, and hydropower, are essential in the global effort to reduce greenhouse gas emissions and combat climate change. As the globe prepares to transition away from fossil fuels, understanding the factors and parameters influencing the penetration of clean energy into existing energy markets has become a critical step. Controversies surrounding the environmental impacts of renewable technologies, variability in market structures, and economic pressures on clean energy companies can complicate this transition.
- Categories:
 81 Views
81 Views
This dataset provides electromagnetic spectrum feature data for target recognition in combat formations, supporting both closed and open set scenarios. It includes three subsets: a closed set with known target types, open set 1 with one unknown target type, and open set 2 with multiple unknown target types. Each dataset contains extracted target features, adjacency matrices representing communication links, and ground truth labels. The dataset covers radar and communication attributes, including carrier frequency, pulse characteristics, modulation types, power, and movement parameters.
- Categories:
19 Views
An automatic waste classification system embedded with higher accuracy and precision of convolution neural network (CNN) model can significantly the reduce manual labor involved in recycling. The ConvNeXt architecture has gained remarkable improvements in image recognition. A larger dataset, called TrashNeXt, comprising 23,625 images across nine categories has been introduced in this study by combining and thoroughly analyzing various pre-existing datasets.
- Categories:
333 Views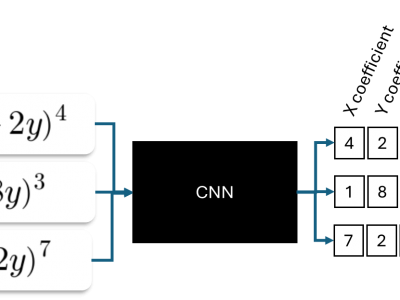
This repository contains the code and documentation for a computational framework that leverages machine learning techniques to enable accurate classification of bacterial species, even closely related strains.
The framework integrates genomic analysis methods, such as motif screening and single nucleotide polymorphism (SNP) extraction, to derive informative features from bacterial genomes. These genomic insights are then fed into machine learning models, which are trained to reliably differentiate between bacterial species based on their distinctive patterns and characteristics.
- Categories:
57 ViewsThe IARPA Space-Based Machine Automated Recognition Technique (SMART) program was one of the first large-scale research program to advance the state of the art for automatically detecting, characterizing, and monitoring large-scale anthropogenic activity in global scale, multi-source, heterogeneous satellite imagery. The program leveraged and advanced the latest techniques in artificial intelligence (AI), computer vision (CV), and machine learning (ML) applied to geospatial applications.
- Categories:
129 Views
The Dash Cam Video Dataset is a comprehensive collection of real-world road footage captured across various Indian roads, focusing on lane conditions and traffic dynamics. Indian roads are often characterized by inconsistent lane markings, unstructured traffic flow, and frequent obstructions, making lane detection and traffic identification a challenging task for autonomous vehicle systems.
- Categories:
418 Views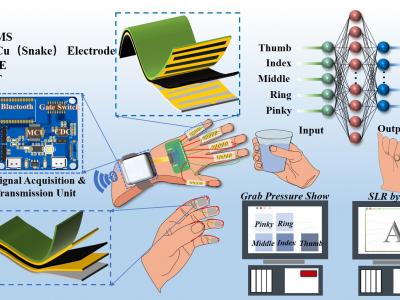
Flexible tactile sensors have attracted significant interest in robotics, medical monitoring, and wearable devices. This paper presents a capacitive flexible tactile sensor that employs a nickel carbonyl powder (NCP)-silicone rubber (SR) composite for pressure and bending sensing, fabricated using magnetic field curing. The performance of the sensor is evaluated independently for pressure and bending sensing, including sensitivity, response time, repeatability, and cyclic stability.
- Categories:
242 Views
The BNS (Bharatiya Nyay Sanhita) dataset is a comprehensive collection of legal texts which was web-scraped.. It consists of chapters and their respective sections, capturing detailed legal content relevant to the recently introduced BNS framework in India. This dataset was gathered using a Python-based web scraping script leveraging Selenium WebDriver, ensuring accuracy and completeness. Available in CSV formats, the dataset facilitates ease of access for legal research, natural language processing (NLP) tasks, and AI-based legal assistance applications.
- Categories:
95 Views
The PhishFOE Dataset is a comprehensive dataset designed for phishing URL detection using machine learning techniques. The dataset contains 101,083 URLs, with labeled features extracted from both the URL structure and HTML content of webpages. It provides insights into key characteristics that distinguish phishing websites from legitimate ones.
-
Total Samples: 101,063
-
Label:
0for Legitimate,1for Phishing
- Categories:
79 Views