Machine Learning
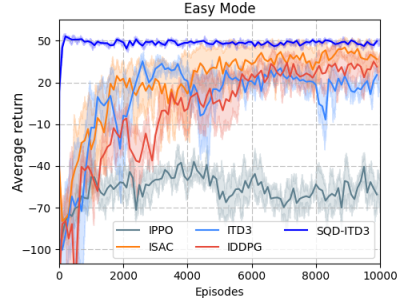
The proposed method is rigorously evaluated against several state-of-the-art algorithms, including ISAC, ITD3, IPPO, and IDDPG, to ensure a comprehensive performance analysis. The experimental data, which is publicly available [here], provides detailed insights into the training and evaluation processes of each algorithm.
- Categories:
 156 Views
156 Views
Dataset Description
This dataset is designed for analyzing and predicting comeback victories in Multiplayer Online Battle Arena (MOBA) games. It is derived from match data where an objective bounty mechanism was active, providing features that highlight differences between teams with and without the bounty advantage. The dataset is ideal for machine learning tasks, such as binary classification and feature importance analysis, and it enables researchers and analysts to explore factors influencing comeback scenarios in competitive gaming.
Dataset Contents:
- Categories:
87 Views
Comprehensive dataset (5000 spectra) of simulated grating biosensor reflections in Excel format. Generated via Lumerical FDTD, it includes 11 parameters (thickness, RI, peak wavelength, FWHM, reflectance, etc.). It is ideal for data visualization, sensor response exploration, and AI/ML benchmarking. The full dataset in Excel format is coming soon! Follow this repository to be notified when it's released. In the meantime, feel free to browse the README for more information about the project.
- Categories:
327 Views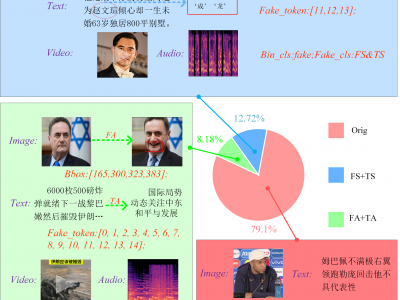
DLSF is the first dedicated dataset for Text-Image Synchronization Forgery (TISF) in multimodal media. The source data for this dataset is scraped from the Chinese news aggregation platform, Toutiao. This dataset includes extensive text, image, and audio-video data from news articles involving politicians and celebrities, featuring samples of both entity-level and attribute-level TISF. It provides comprehensive annotations, including labels for text-image authenticity, types of TISF, image forgery regions, and text forgery tokens.
- Categories:
109 Views
This dataset provides a comprehensive record of wind power generation and its relationship with oceanic-atmospheric indices, facilitating advanced forecasting and analytical research in renewable energy. The dataset comprises 12 input parameters, including average wind speed, which serves as a crucial predictor, while wind power generation acts as the output variable.
- Categories:
166 Views
The recent developments in the field of the Internet of Things (IoT) bring alongside them quite a few advantages. Examples include real-time condition monitoring, remote control and operation and sometimes even remote fault remediation. Still, despite bringing invaluable benefits, IoT-enriched entities inherently suffer from security and privacy issues. This is partially due to the utilization of insecure communication protocols such as the Open Charge Point Protocol (OCPP) 1.6. OCPP 1.6 is an application-layer communication protocol used for managing electric vehicle chargers.
- Categories:
753 Views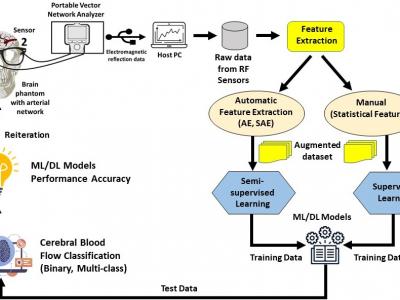
This dataset provides measurements of cerebral blood flow using Radio Frequency (RF) sensors operating in the Ultra-Wideband (UWB) frequency range, enabling non-invasive monitoring of cerebral hemodynamics. It includes blood flow feature data from two arterial networks, Arterial Network A and Arterial Network B. Statistical features were manually extracted from the RF sensor data, while autonomous feature extraction was performed using a Stacked Autoencoder (SAE) with architectures such as 32-16-32, 64-32-16-32-64, and 128-64-32-16-32-64-128.
- Categories:
202 Views
The Metaverse Gait Authentication Dataset (MGAD) is a large-scale gait dataset designed for biometric authentication in virtual environments.
- Categories:
250 Views
We curated and release a real-world medical clinical dataset, namely MedCD, in the context of building generative artificial intelligence (AI) applications in the clinical setting. The MedCD dataset is one of the accomplishments from our longitudinal applied AI research and deployment in a tertiary care hospital in China. First, the dataset is real and comprehensive, in that it was sourced from real-world electronic health records (EHRs), clinical notes, lab examination reports and more.
- Categories:
268 Views
The data set is a time series of gas concentration collected continuously in a coal mine in China. The data set collects data once every hour. The gas concentration record period in this data set is from 0 : 00 on January 1,2021 to 15 : 00 on March 27,2021. The data set only contains two attributes : time and gas concentration on the working face.
- Categories:
79 Views