Machine Learning

JVNV is a Japanese emotional speech corpus with verbal content and nonverbal vocalizations whose scripts are generated by a large-scale language model.
Existing emotional speech corpora lack not only proper emotional scripts but also nonverbal vocalizations (NVs) that are essential expressions in spoken language to express emotions.
We propose an automatic script generation method to produce emotional scripts by providing seed words with sentiment polarity and phrases of nonverbal vocalizations to ChatGPT using prompt engineering.
- Categories:
 542 Views
542 Views
Social Media Big Dataset for Research, Analytics, Prediction, and Understanding the Global Climate Change Trends is focused on understanding the climate science, trends, and public awareness of climate change. The use of dataset for analytics of climate change trends greatly helps in researching and comprehending global climate change trends.
- Categories:
3649 Views
The Numerical Latin Letters (DNLL) dataset consists of Latin numeric letters organized into 26 distinct letter classes, corresponding to the Latin alphabet. Each class within this dataset encompasses multiple letter forms, resulting in a diverse and extensive collection. These letters vary in color, size, writing style, thickness, background, orientation, luminosity, and other attributes, making the dataset highly comprehensive and rich.
- Categories:
492 Views
A crime is a deliberate act that can cause physical or psychological harm, as well as property damage or loss, and can lead to punishment by a state or other authority according to the severity of the crime. The number and forms of criminal activities are increasing at an alarming rate, forcing agencies to develop efficient methods to take preventive measures. In the current scenario of rapidly increasing crime, traditional crime-solving techniques are unable to deliver results, being slow paced and less efficient.
- Categories:
464 Views
Our large scale alpine land cover dataset consists of 229'535 very high-resolution aerial images (50cm) and digital elevation model (50cm) with land cover annotations produced by experts in photo-interpretration . The nine land cover types in our study area include bedrock, bedrock with grass, large blocks, large blocks with grass, scree, scree with grass, water area, forest and glacier. The distribution of pixels among classes presents a typical case of a long-tailed distribution with an imbalance factor, defined as the ratio of the most frequent to the rarest class, close to 1000.
- Categories:
248 Views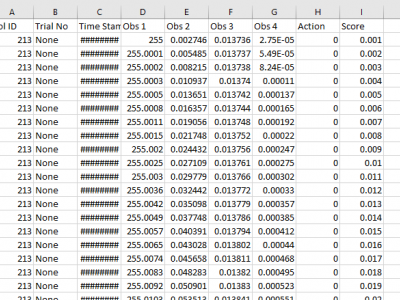
The instantaneous state (situation) of the game was constituted by four values: the cart position, the cart speed, the pole angle to the vertical axis, and the pole angular velocity.
For each action taken by the human player in the game, a tuple containing the four values representing the current game situation, along with the action and reward obtained (utility), is recorded as a situation-decision-utility (SDU) tuple.
3 types of actions have been recorded: Move left (-1), move rght (1) and no action (0).
- Categories:
19 Views
The first part of the data set contains the monthly recorded spread of covid-19 across the 6 geopolitical zones of Nigeria for the period of March 2020 to September 2022.
The second part of the data set contains the recorded covid-19 spread during religious festivals across the 6 geopolitical zones of Nigeria.
The third part contains the projected population densities of the 36 states of Nigeria alongside the number of covid-19 test centres in each state.
- Categories:
342 Views
This dataset features a wide range of synthetic American Sign Language (ASL) digits, spanning numbers 0 through 9. These ASL sign representations were meticulously crafted using Unity software, resulting in dynamic 3-D scenes set against diverse backgrounds. To enhance the dataset's comprehensiveness, it includes contributions from three distinct subjects, adding a rich variety of ASL digit gestures. This diversity makes it a valuable resource for researchers interested in ASL digit recognition and gesture analysis.
- Categories:
386 Views
This dataset is derived from a research paper proposing a wireless localization correction methodology based on Convolutional Neural Networks (CNN). The approach involves feature extraction from maps that depict both line of sight (LOS) and non-line of sight (NLOS) effects. The research includes four prediction tasks, categorizing CNN models based on building distribution and propagation mode, resulting in models with low prediction loss. Additionally, an error compensation scheme is designed using CNN-predicted localization errors.
- Categories:
155 Views
Quantifying performance of methods for tracking and mapping tissue in endoscopic environments is essential for enabling image guidance and automation of medical interventions and surgery. Datasets developed so far either use rigid environments, visible markers, or require annotators to label salient points in videos after collection. These are respectively: not general, visible to algorithms, or costly and error-prone. We introduce a novel labeling methodology along with a dataset that uses said methodology, Surgical Tattoos in Infrared (STIR).
- Categories:
1972 Views