
Race track dataset for a mobile fun racer. Used for the evaluation of a not yet published journal paper. Specific reference will be added here once the paper has been accepted and published.
- Categories:
Race track dataset for a mobile fun racer. Used for the evaluation of a not yet published journal paper. Specific reference will be added here once the paper has been accepted and published.

The TripAdvisor online airline review dataset, spanning from 2016 to 2023, provides a comprehensive collection of passenger feedback on airline services during the COVID-19 pandemic. This dataset includes user-generated reviews that capture sentiments, preferences, and concerns, allowing for an in-depth analysis of shifting customer priorities in response to pandemic-related disruptions. By examining these reviews, the dataset facilitates the study of evolving passenger expectations, changes in service perceptions, and the airline industry's adaptive strategies.
This dataset can be used for vulnerability detection. This repository is devised to explain vulEmbedding,
First "altKlasörTaraTahmin.R" file is for searching code files to generate suitable numeric matrix,
createKeywordMatrix.R is for generating keyword matrix, thereby checking vulnerabilities,
sphericalLabeling.R is for generating spherical labeling.
Final you can run deepnetVersion2.R to produce vulnerability prediction.
If you are not concered with generating data from source code,

This dataset comprises 33,800 images of underwater signals captured in aquatic environments. Each signal is presented against three types of backgrounds: pool, marine, and plain white. Additionally, the dataset includes three water tones: clear, blue, and green. A total of 12 different signals are included, each available in all six possible background-tone combinations.

The proper evaluation of food freshness is critical to ensure safety, quality along with customer satisfaction in the food industry. While numerous datasets exists for individual food items,a unified and comprehensive dataset which encompass diversified food categories remained as a significant gap in research. This research presented UC-FCD, a novel dataset designed to address this gap.
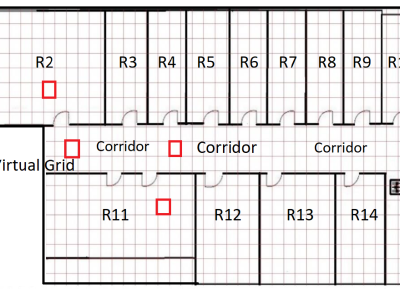
The JU-Impact Radiomap Dataset is a comprehensive dataset designed for research and development in indoor positioning systems. It comprises 5431 instances characterized by readings from 105 static Wi-Fi Access Points (APs) and spans 152 distinct virtual grids. Each virtual grid represents a 1x1 square meter area, derived by dividing a physical floor of a university building into reference coordinate points (x, y). The dataset was collected over a period of 21 days using four mobile devices: Samsung Galaxy Tab, Moto G, Redmi Note 4, and Google Pixel.

To further evaluate the practical performance of HPDM, we apply it to detect defects in actual industrial circuit boards. Various defects, such as board, lifting, and ffipping defects, occur on the circuit board because of external forces imposed during the placement and soldering processes .A real industrial circuit board defect detection dataset is collected and presented. This dataset includes five different categories of components with various real multiscale defects.
The dataset are served for community-imbalanced graph sampling algorithm performance experiments. In the algorithm performance experiment, we selected 30 graph datasets, 15 of which were derived from real-world graph datasets (https://snap.stanford.edu/data/), and 15 were adapted from real-world datasets or simulated datasets.

The Human voice Natural Language from On-demand media (HENLO) dataset is a high-quality emotional speech dataset created to address the need for representative and realistic data in speech emotion recognition research. Unlike many existing datasets, which rely on simulated emotions performed by untrained speakers or directed participants, HENLO sources its data from professionally produced films and podcasts available on Media On-Demand (MOD).
This dataset supports a systematic review on the integration of Digital Twins (DT), Extended Reality (XR), and Artificial Intelligence (AI) in Reconfigurable Manufacturing Systems (RMS). The data was collected during a search performed on March 3, 2024, using the Scopus database. Articles published since 2018 were screened based on predefined inclusion and exclusion criteria, resulting in 37 articles selected for qualitative analysis.