Signal Processing

A deep learning (DL)--based detector is proposed for underwater acoustic (UWA) communication systems using orthogonal chirp division multiplexing with index modulation (OCDM-IM). The proposed high-performance and lightweight network integrates the detection of the index bits and the carrier bits as a whole, employing a squeeze-and-excitation (SE) mechanism enhanced residual neural network (ResNet) cascaded with a bidirectional gated recurrent unit (BiGRU) to detect OCDM-IM signals.
- Categories:
 179 Views
179 Views
This dataset addresses the challenge of limited vocal recordings available in secondary datasets, particularly those that predominantly feature foreign accents and contexts. To enhance the accuracy of our solution tailored for Sri Lankans, we employed primary data-gathering methods.
The dataset comprises vocal recordings from a sample population of youth. Participants were instructed to read three specific sentences designed to capture a range of vocal tones:
- Categories:
235 Views
In this letter, a deep learning (DL)--based detector is proposed for underwater acoustic (UWA) communication systems using orthogonal chirp division multiplexing with index modulation (OCDM-IM). The proposed high-performance and lightweight network integrates the detection of the index bits and the carrier bits as a whole, employing a squeeze-and-excitation (SE) mechanism enhanced residual neural network (ResNet) cascaded with a bidirectional gated recurrent unit (BiGRU) to detect OCDM-IM signals.
- Categories:
198 Views
Experiment Details:
- Categories:
1682 Views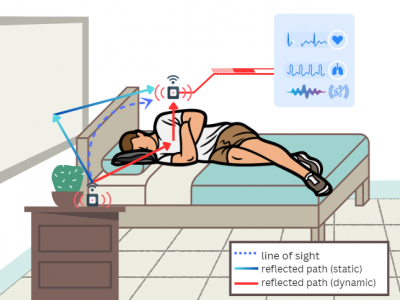
This dataset contains Wi-Fi sensing data using Channel State Information (CSI) for various sleep disturbance parameters, from respiratory disturbances, to motion-based disturbances from posture shifts, leg restlessness and confusional arousals.The Wi-Fi CSI data was collected using the Wi-Fi module on the ESP32 Microcontroller units using the esp32-csi-tool.The Wi-Fi CSI respiratory disturbance data is accompanied by respiration belt data taken with the Wi-Fi measurements simultaneously using the Neulog NUL-236 respiration belt logger as ground truth.
- Categories:
1211 Views
Voice Pre-processing and Quality Assessment Dataset (VPQAD), a scalable resource has been developed to validate various pre-processing techniques and improve voice signal quality in noisy environments. The dataset comprises voice recordings from 50 participants aged 18 to 40, captured in controlled real-life conditions using Audio Technica AT2020 and SHURE SM58 microphones. These high-quality recordings, made under diverse noise levels and settings, could be used for testing and developing voice enhancement algorithms.
- Categories:
273 Views
A set of non-stationary target vital sign signals measured by the FMCW radar, with data from a total of four testers, were tested for five sets of one minute each, with the testers approximately 1m away from the radar, in a non-stationary state. The radar-measured vital sign signals are stored in a .bin format file, the radar parameters are set in a Logfile.txt file, and the remaining two .txt files are the reference data collected with the respiratory and heartbeat sensors.
- Categories:
573 Views
Common Randomness (CR) can be considered as a resource in our future communication systems that will assist in various operations, such as cryptographic encryption in wireless communication, improving identification capacity for identification codes. In wireless communication, CR can be conveniently generated by reading the reciprocal channel properties between two wireless terminals, and by sending pilot signals to each other using the time division duplexing (TDD)-based half-duplexing method. In the channel probing stage, reciprocal channel characteristics are measured.
- Categories:
230 Views
This is the millimeter wave radar gesture recognition gesture dataset corresponding to paper <Gesture Recognition Using MIMO Radar Point Clouds with Targeted Signal Processing for Resource-Limited Platforms>. The file is stored in the. npy format of the numpy library in Python. It contains 4 gestures and 1 unrelated set of data, with a total of 5 categories. There are a total of 6000 pieces of data in each category, and each piece of raw data is packaged in a compressed package. The output screenshot of the script shows the details.
- Categories:
210 Views
The limited availability of Guitar notes datasets hinders the training of any artificial intelligence model in this field. TaptoTab dataset aims to fill this gap by providing a collection of notes recordings. This dataset is collected as part of an honours project at the Faculty of Computer and Information Sciences, Ain Shams University. The dataset is composed of audio data that has been self-collected, focusing on capturing a comprehensive range of guitar notes. The dataset consists of recordings of guitar notes played on each of the six strings, covering up to the 12th fret.
- Categories:
697 Views