Machine Learning

This is a dataset is an example of a distribution of 20 correlated Bernoulli random variables.
- Categories:
 359 Views
359 Views
Microwave-based breast cancer detection is a growing field that has been investigated as a potential novel method for breast cancer detection. Breast microwave sensing (BMS) systems use low-powered, non-ionizing microwave signals to interrogate the breast tissues. While some BMS systems have been evaluated in clinical trials, many challenges remain before these systems can be used as a viable clinical option, and breast phantoms (breast models) allow for rigorous and controlled experimental investigations.
- Categories:
2419 Views
This dataset is a hand noted dataset that consists of two categories, evasion and normal methods. By evasion methods we mean the methods that are used by Android malware to hide their malicious payload, and hinder the dynamic analysis. Normal methods are any other methods that cannot be used as evasion techniques. Also, the evasion methods are categorized into six categories: File access, Integrity check, Location, SMS, Time, Anti-emulation. This dataset can be used by any ML or DL approaches to predict new evasion techniques that can be used by malware to hinder the dynamic analysis.
- Categories:
464 Views
In this paper, the security-aware robust resource allocation in energy harvesting cognitive radio networks is considered with cooperation between two transmitters while there are uncertainties in channel gains and battery energy value. To be specific, the primary access point harvests energy from the green resource and uses time switching protocol to send the energy and data towards the secondary access point (SAP).
- Categories:
518 Views
1.Visualization of convolutional neural network layers for one participant at ROI 301 * 301
2.Convolutional neural network structure analysis in Matlab
3.Convolutional neural network Matlab code
4.Videos of brightness mode (B-mode) ultrasound images from two participants during the recorded walking trials at 5 different speeds
- Categories:
744 Views
DIDA is a new image-based historical handwritten digit dataset and collected from the Swedish historical handwritten document images between the year 1800 and 1940. It is the largest historical handwritten digit dataset which is introduced to the Optical Character Recognition (OCR) community to help the researchers to test their optical handwritten character recognition methods. To generate DIDA, 250,000 single digits and 200,000 multi-digits are cropped from 75,000 different document images.
- Categories:
1611 Views
The CoVID19-FNIR dataset contains news stories related to CoVID-19 pandemic fact-checked by expert fact-checkers. CoVID19-FNIR is a CoVID-19-specific dataset consisting of fact-checked fake news scraped from Poynter and true news from the verified Twitter handles of news publishers. The data samples were collected from India, The United States of America, and European regions and consist of online posts from social media platforms between February 2020 to June 2020. The dataset went through prepossessing steps that include removing special characters and non-vital information.
- Categories:
6382 Views
The accompanying dataset for the CVSports 2021 paper: DeepDarts: Modeling Keypoints as Objects for Automatic Scoring in Darts using a Single Camera
Paper Abstract:
- Categories:
6886 Views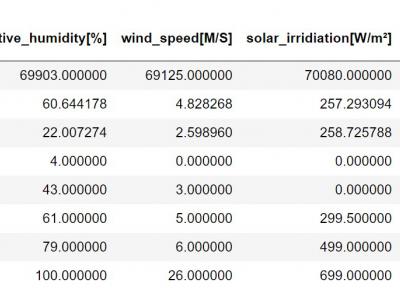
The heating and electricity consumption data are the results of an energy audit program aggregated for multiple load profiles of a residential customer. These profiles include HVAC systems loads, convenience power, elevator, etc. The datasets are gathered between December 2010 and November 2018 with a one-hour timestep resolution, thereby containing 140,160 measurements, half of which is for heat or electricity. In addition to the historical energy consumption values, a concatenation of weather variables is also available.
- Categories:
7533 Views
Rembrandt contains data generated through the Glioma Molecular Diagnostic Initiative from 874 glioma specimens comprising approximately 566 gene expression arrays, 834 copy number arrays, and 13,472 clinical phenotype data points. These data are currently housed in Georgetown University's G-DOC System and are described in a related manuscript .
- Categories:
437 Views