Machine Learning
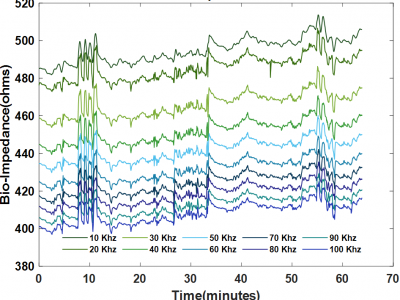
This dataset is taken from 20 subjects over a duration of 1 hour where experiments were done on the upper body bio-impedance with the following objectives:
a) Evaluate the effect of externally induced perturbance at the SE interface caused by motion, applied pressure, temperature variation and posture change on bio-impedance measurements.
b) Evaluate the degree of distortion due to artefact at multiple frequencies (10kHz-100kHz) in the bio-impedance measurements.
- Categories:
 585 Views
585 Views

The AOLAH databases are contributions from Aswan faculty of engineering to help researchers in the field of online handwriting recognition to build a powerful system to recognize Arabic handwritten script. AOLAH stands for Aswan On-Line Arabic Handwritten where “Aswan” is the small beautiful city located at the south of Egypt, “On-Line” means that the databases are collected the same time as they are written, “Arabic” cause these databases are just collected for Arabic characters, and “Handwritten” written by the natural human hand.
- Categories:
1022 ViewsSome 6G use cases include augmented reality and high-fidelity holograms, with this information flowing through the network. Hence, it is expected that 6G systems can feed machine learning algorithms with such context information to optimize communication performance. This paper focuses on the simulation of 6G MIMO systems that rely on a 3-D representation of the environment as captured by cameras and eventually other sensors. We present new and improved Raymobtime datasets, which consist of paired MIMO channels and multimodal data.
- Categories:
398 Views
LATIC is focusing on non-native Mandarin Chinese learners. It is an annotated non-native speech database for Chinese, which is fully open-source can get online for any purpose use. The related using area can be automatic speech scoring, evaluation, derivation—L2 teaching, Education of Chinese as Foreign Language, etc. We are aiming to provide a relatively small-scale and highly efficient training deviation dataset. For this target, four chosen non-native Chinese speaker participated in this project, and their mother tongue (L1s) varies from Russian, Korean, French and Arabic.
- Categories:
1741 Views
Recent advances in computational power availibility and cloud computing has prompted extensive research in epileptic seizure detection and prediction. EEG (electroencephalogram) datasets from ‘Dept. of Epileptology, Univ. of Bonn’ and ‘CHB-MIT Scalp EEG Database’ are publically available datasets which are the most sought after amongst researchers. Bonn dataset is very small compared to CHB-MIT. But still researchers prefer Bonn as it is in simple '.txt' format. The dataset being published here is a preprocessed form of CHB-MIT. The dataset is available in '.csv' format.
- Categories:
11952 Views
KROCO is an acronym for Kinesthetic Robot Contacts. The dataset consists of Learning from Demonstration (LfD, aka Programming by Demonstration (PbD)) samples that were collected via kinesthetic teaching. Each labeled sample is a contact-based (force-based) interaction with the environment.
- Categories:
210 Views
Simulation code for the paper: "AoI Minimization in Energy Harvesting and Spectrum Sharing Enabled 6G Networks"
we use a neural network to approximate the Q-value function. The state is given as the input and the Q-value of all possible actions is generated as the output.
- Categories:
522 Views
This dataset consists of temporal and temperature drift characteristics of Si3N4-gate iSFET andsupplementary files
- Categories:
431 Views
Dataset used in the article "The Reverse Problem of Keystroke Dynamics: Guessing Typed Text with Keystroke Timings". CSV files with dataset results summaries, the evaluated sentences, detailed results, and scores. Results data contains training and evaluation ARFF files for each user, containing features of synthetic and legitimate samples as described in the article. The source data comes from three free text keystroke dynamics datasets used in previous studies, by the authors (LSIA) and two other unrelated groups (KM, and PROSODY, subdivided in GAY, GUN, and REVIEW).
- Categories:
505 Views