Machine Learning

Most of existing audio fingerprinting systems have limitations to be used for high-specific audio retrieval at scale. In this work, we generate a low-dimensional representation from a short unit segment of audio, and couple this fingerprint with a fast maximum inner-product search. To this end, we present a contrastive learning framework that derives from the segment-level search objective. Each update in training uses a batch consisting of a set of pseudo labels, randomly selected original samples, and their augmented replicas.
- Categories:
 2063 Views
2063 Views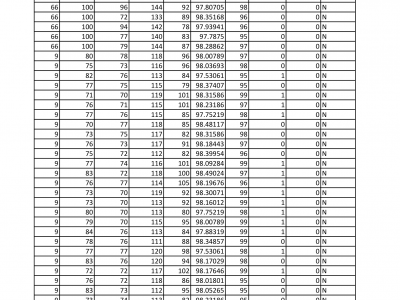
The given Dataset is record of different age group people either diabetic or non diabetic for theie blood glucose level reading with superficial body features like body temperature, heart rate, blood pressure etc.
The main purpose of the dataset is to understand the effect of blood glucose level on human body.
The different superficial body parameters show sifnificant variation according to change in blood glucose level.
- Categories:
10158 Views
The data of machine learning attacks for MF-PUF
- Categories:
73 Views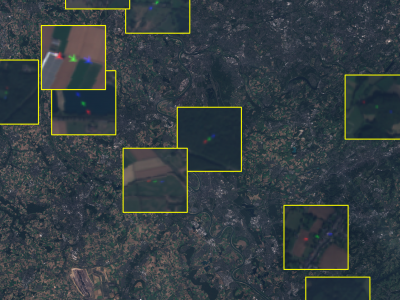
This dataset contains satellite images of areas of interest surrounding 30 different European airports. It also provides ground-truth annotations of flying airplanes in part of those images to support future research involving flying airplane detection. This dataset is part of the work entitled "Measuring economic activity from space: a case study using flying airplanes and COVID-19" published by the IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing. It contains modified Sentinel-2 data processed by Euro Data Cube.
- Categories:
2169 Views
Parallel fractional hot-deck imputation (P-FHDI) is a general-purpose, assumption-free tool for handling item nonresponse in big incomplete data by combining the theory of FHDI and parallel computing. FHDI cures multivariate missing data by filling each missing unit with multiple observed values (thus, hot-deck) without resorting to distributional assumptions. P-FHDI can tackle big incomplete data with millions of instances (big-n) or 10, 000 variables (big-p).
- Categories:
367 Views
Context
This dataset consists of subject wise daily living activity data, which is acquired from the inbuilt accelerometer and gyroscope sensors of the smartphones.
Content
The smartphone was mounted on the waist and front pockets of the users. All the different activities were performed in a laboratory except Running, which was performed on a Football Playground.
Smartphone used: Poco X2 and Samsung Galaxy A32s
Inbuild Sensors used: Accelerometer and Gyroscope
Ages: All subjects are Above 23 years
- Categories:
2732 Views
Packet delivery ratio data collected for the article Wireless-Sensor Network Topology Optimization in Complex Terrain: A Bayesian Approach. Published in the IEEE Internet of Things Journal.
- Categories:
145 Views
The data set contains inspections conducted by the Norwegian Labour Inspection Authority (NLIA) between 2012 and 2019. Each row in the dataset contains a control point, non-compliance indicator for the control point and industry code / municipality / county of the inspected organisation.
- Categories:
361 Views
<p>This is the image dataset for satellite image processing which is a collection therml infrared and multispectral images .</p>
- Categories:
3325 Views
The "RetroRevMatchEvalICIP16" dataset provides a retrospective reviewer recommendation dataset and evaluation for IEEE ICIP 2016. The methodology via which the recommendations were obtained and the evaluation was performed is described in the associated paper.
Y. Zhao, A. Anand, and G. Sharma, “Reviewer recommendations using document vector embeddings and a publisher database: Implementation and evaluation,” IEEE Access, vol. 10, pp. 21 798–21 811, 2022. https://doi.org/10.1109/ACCESS.2022.3151640
- Categories:
280 Views