Machine Learning

To train the machine learning model, a dataset was generated containing data for «Budennovskoye» field, part of which is shown in title figure. (AR and SP are given for 90 centimeter intervals, for which, in turn, the actual values K_fpo. obtained by pumping out (pump out) was determined. As a result, the input variable set consisted of 19 values, including the rock code (AR, SP). The target column isK_f_pump_out .
- Categories:
 424 Views
424 Views

This data set contains tweets related to haptics from 2008 to 2021.
- Categories:
117 Views
ABSTRACT
Europe is covered by distinct climatic zones which include semiarid, the Mediterranean, humid subtropical, marine,
humid continental, subarctic, and highland climates. Land use and land cover change have been well documented in the
past 200 years across Europe1where land cover grassland and cropland together make up 39%2. In recent years, the
agricultural sector has been affected by abnormal weather events. Climate change will continue to change weather
- Categories:
476 Views
Data used for evaluation of the Chameleon system. We use it to evaluate capabilities of sensor fusion system that is able to adapot to multiple envrionemnts and monitor activity states within a room. The data set is divided by the two deployments and includes inforamtion for both of the sensors used to test the system. We include two weeks worth of data along with training and testing accuracy results.
- Categories:
1006 Views
The datasets were collected by operating the testbed (simulation of small-scale of IEC 61850-compliant SASs) under four types of behaviours: 1) normal operation when no unusual events happen; 2) emergency operation when non-malicious events (e.g., short-circuit faults) happen; 3) an attack under normal operation to disrupt energy transmission; and 4) an attack under emergency operation to stop protection mechanisms or trigger undesirable protection operations.
- Categories:
191 Views
This is the dataset for the paper Bayesian Inference of Sector Orientation in LTE Networks based on End-User Measurements published at VTC 2021 - Fall.
It includes a set of Drive-Test RSRP Pathloss Measurements with their relative position to the corresponding eNodeB. In total it contains data for 91 three-sector eNodeBs, which results in 273 sectors.
- Categories:
595 Views
It distinguishes direct causes from direct effects of a target variable from multiple manipulated datasets with unknown manipulated variables and nonidentical data distributions.
- Categories:
105 Views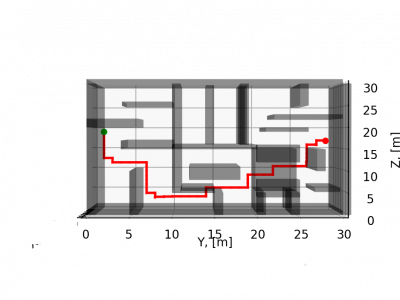
This dataset presents a collection of coordinates that belongs to paths generated with a 3D disjstkra algorithm,in diferents enviroments,with a grid size equal to one. The output is a six dimension vector that represents the action taken by the agent (z+,z-,y+,y-,x+,x-) based on his pose, sensors readings and the target.
- Categories:
237 Views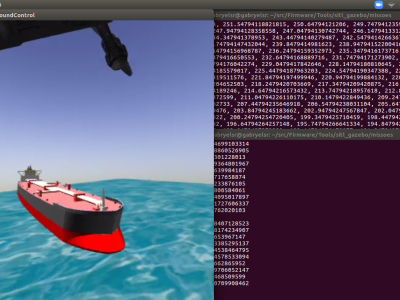
This dataset is composed of 580 mannually annotated images of shuttle tanker vessels, FPSO and FSO oil rigs. The images were obtained from simple Google search and some of them are 3D models generated from modelling software and used in Gazebo robotics simulations. The images were annotated using Computer Vision Annotation Tool (CVAT), and for each of them there is a .xml Pascal VOC file where the boxes are. The annotated objects were the ship itself and its generic regions, named as bow, mid-ship and stern.
- Categories:
309 Views