*.txt
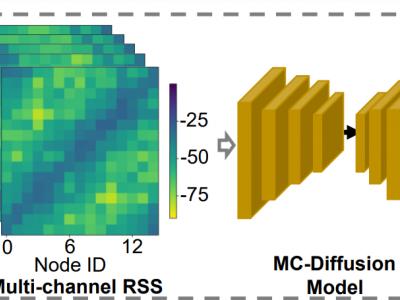
We introduce a wireless potato root tuber sensing (WPS) dataset comprising multi-channel received signal strength(RSS) data from a wireless network and ground truth annotations for potato root tubers. We design a testbed called spin, which is based on a multi-channel wireless network, the wireless network is consist of 16 TI CC25231 nodes deploy on a white rack, using this testbed, we conduct extensive measurement expriments. We first perform expriments in a static environment.
- Categories:
 163 Views
163 Views
This dataset is utilized for adversarial camouflage generation. We collect vehicle datasets in the CARLA simulation environment under 16 weather conditions. These weather conditions are generated by combining four sun altitude angles (-90°, 10°, 45°, 90°) with four fog densities (0, 25, 50, 90). Within each weather scenario, we randomly choose 16 locations for texture generation. Camera transformation values are randomly selected within specified intervals at each car location.
- Categories:
442 Views
This dataset webpage contains datasets of exisiting and proposed models:
- centrifugalpump1.zip
- centrifugalpump2.zip
- centrifugalpump3.zip
B Model of Fault And Short-Circuit Analysis of Centrifugal Pump
presented in my last Speaker Presentation in Conference - 2025*.
- Categories:
396 Views
This dataset webpage contains datasets and models
- inductionmotor1.zip
- inductionmotor2.zip
- inductionmotor3.zip
- pmsm1.zip
- pmsm2.zip
- pmsm3.zip
- BLDC1.zip
- BLDC1.zip
presented in my 3rd last Speaker Presentation in Conference - 2025*.
- Categories:
395 Views
Smart focal-plane and in-chip image processing has emerged as a crucial technology for vision-enabled embedded systems with energy efficiency and privacy. However, the lack of special datasets providing examples of the data that these neuromorphic sensors compute to convey visual information has hindered the adoption of these promising technologies.
- Categories:
184 Views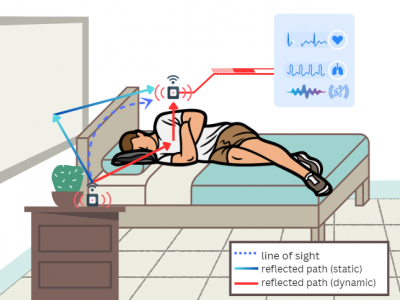
This dataset contains Wi-Fi sensing data using Channel State Information (CSI) for various sleep disturbance parameters, from respiratory disturbances, to motion-based disturbances from posture shifts, leg restlessness and confusional arousals.The Wi-Fi CSI data was collected using the Wi-Fi module on the ESP32 Microcontroller units using the esp32-csi-tool.The Wi-Fi CSI respiratory disturbance data is accompanied by respiration belt data taken with the Wi-Fi measurements simultaneously using the Neulog NUL-236 respiration belt logger as ground truth.
- Categories:
1130 Views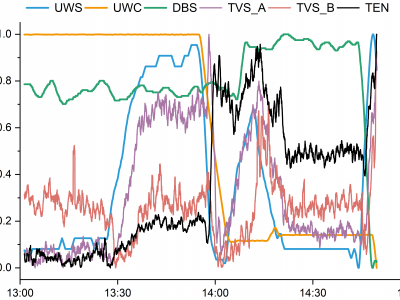
This graph illustrates the visualization trend of a subset of the dataset I have uploaded, which comprises 6500*9 data points. The dataset consists of nine columns representing underwater speed (UWS), underwater course (UWC), depth below the surface (DBS), rate of change in speed (RCS), rate of change in course (RCC), rate of change in depth (RCD), trend A and B of vibrational signals (TVS_A, TVS_B) and electromagnetic noise trend (TEN) recorded by the AUV.
- Categories:
135 Views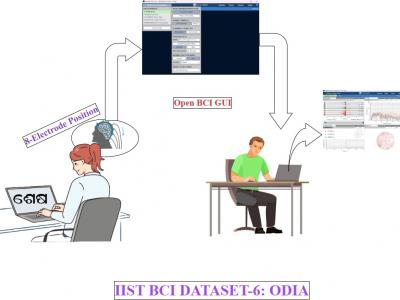
Brain-Computer Interface (BCI) is a technology that enables direct communication between the brain and external devices, typically by interpreting neural signals. BCI-based solutions for neurodegenerative disorders need datasets with patients’ native languages. However, research in BCI lacks insufficient language-specific datasets, as seen in Odia, spoken by 35-40 million individuals in India. To address this gap, we developed an Electroencephalograph (EEG) based BCI dataset featuring EEG signal samples of commonly spoken Odia words.
- Categories:
363 Views
executing the coding and topological experiments while simulating the automation pyramid model we constructed with Ifogsim. the pyramid's layers, the changes that occur at each level, and the connections between clouds and communication at every level.executing the coding and topological experiments while simulating the automation pyramid model we constructed with Ifogsim.
- Categories:
96 Views
Background
Effective retraining of foot elevation and forward propulsion is essential in stroke survivors’ gait rehabilitation. However, home-based training often lacks valuable feedback. eHealth solutions based on inertial measurement units (IMUs) could offer real-time feedback on fundamental gait characteristics. This study aimed to investigate the effect of providing real-time feedback through an eHealth solution on foot strike angle (FSA) and forward propulsion in people with stroke.
- Categories:
27 Views