*.txt

Satellite attitude determination is critical for accurately measuring and controlling a satellite’s orientation in orbit using a variety of sensors and methods. Currently, low-low Satellite-to-Satellite Tracking (ll-SST) missions—such as GRACE(-FO)—and upcoming missions like Magic primarily rely on quaternion data from onboard star camera sensors. To enhance attitude determination, we propose a GSCF fusion method.
- Categories:
 7 Views
7 Views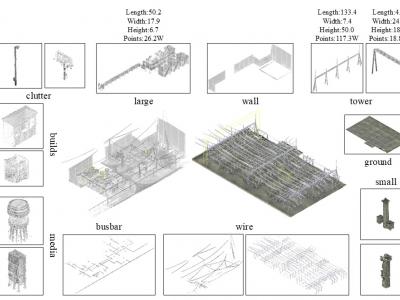
ElecsDataset is a specialized 3D semantic segmentation dataset designed for substation environments. It addresses the shortage of domain-specific annotated data in the field of substation 3D semantic segmentation. This dataset offers high-resolution, meticulously annotated point clouds that capture complex equipment structures and real-world occlusions. It consists of data collected from three substations of varying scales. The dataset is systematically partitioned into 6 distinct spatial regions with heterogeneous dimensions.
- Categories:
125 ViewsElecsDataset is a specialized 3D semantic segmentation dataset designed for substation environments. It addresses the shortage of domain-specific annotated data in the field of substation 3D semantic segmentation. This dataset offers high-resolution, meticulously annotated point clouds that capture complex equipment structures and real-world occlusions. It consists of data collected from three substations of varying scales. The dataset is systematically partitioned into 6 distinct spatial regions with heterogeneous dimensions.
- Categories:
Views
Gramatika is a syntectic GEC dataset for Indonesian. The Gramatika dataset has a total of 1.5 million sentences with 4,666,185 errors. Of all sentences, only 30,000 (2%) are correct sentences with no mistakes. Each sentence has a maximum of 6 errors, and there can only be 2 of the same error type in each sentence.We also split the dataset into three splits: train, dev, and test splits, with the proportion of 8:1:1 (with the size of 1,199,705, 150,171, and 150,124 sentences, respectively).
- Categories:
20 Views
Gramatika is a syntectic GEC dataset for Indonesian. The Gramatika dataset has a total of 1.5 million sentences with 4,666,185 errors. Of all sentences, only 30,000 (2%) are correct sentences with no mistakes. Each sentence has a maximum of 6 errors, and there can only be 2 of the same error type in each sentence.We also split the dataset into three splits: train, dev, and test splits, with the proportion of 8:1:1 (with the size of 1,199,705, 150,171, and 150,124 sentences, respectively).
- Categories:
5 Views
This paper explores the cryptanalysis of the ASCON algorithm, a lightweight cryptographic method designed for applications like the Internet of Things (IoT). We utilize deep learning techniques to identify potential vulnerabilities within ASCON's structure. First, we provide an overview of how ASCON operates, including key generation and encryption processes.
- Categories:
164 Views
This paper explores the cryptanalysis of the ASCON algorithm, a lightweight cryptographic method designed for applications like the Internet of Things (IoT). We utilize deep learning techniques to identify potential vulnerabilities within ASCON's structure. First, we provide an overview of how ASCON operates, including key generation and encryption processes.
- Categories:
36 Views
This dataset accompanies the study “Universal Metrics to Characterize the Performance of Imaging 3D Measurement Systems with a Focus on Static Indoor Scenes” and provides all measurement data, processing scripts, and evaluation code necessary to reproduce the results. It includes raw and processed point cloud data from six state-of-the-art 3D measurement systems, captured under standardized conditions. Additionally, the dataset contains high-speed sensor measurements of the cameras’ active illumination, offering insights into their optical emission characteristics.
- Categories:
146 Views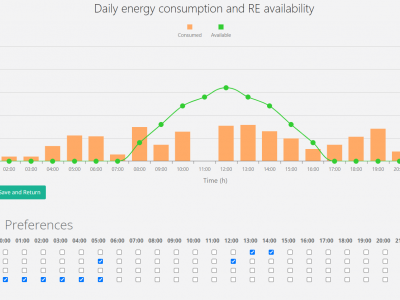
Twelve (12) realistic datasets encapsulating residents’ preferences, with each dataset representing the appliance-usage preferences expressed for a variant set of households by their respective residents for a specific season and day. The preferences were extracted from the REFIT dataset, a public 500MB dataset which contains real kW readings of the power output for the most energy-intensive shiftable/real-time appliances in 20 households in the UK, between September 2013 and July 2015.
- Categories:
282 Views
This dataset contains human motion data collected using inertial measurement units (IMUs), including accelerometer and gyroscope readings, from participants performing specific activities. The data was gathered under controlled conditions with verbal informed consent and includes diverse motion patterns that can be used for research in human activity recognition, wearable sensor applications, and machine learning algorithm development. Each sample is labeled and processed to ensure consistency, with raw and augmented data available for use.
- Categories:
84 Views