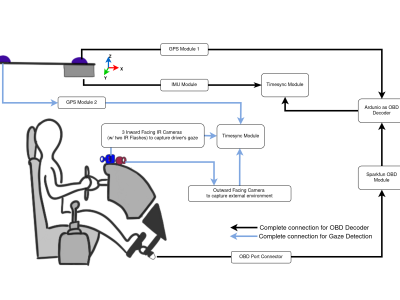
This is a videoconference between a witness about murders who is a victim of many crimes and a law firm. This witness is called Colin Paul Gloster. This law firm is called Pais do Amaral Advogados.
\begin{quotation}``A significant part of the background of eh this process is that Hospital
Sobral Cid tortured me during 2013 eh but eh this process is actually
about consequences eh thru through a later process [. . .] To obscure eh
this torture of 2013, eh a new show trial was intitiated. Its process was
- Categories: