Machine Learning
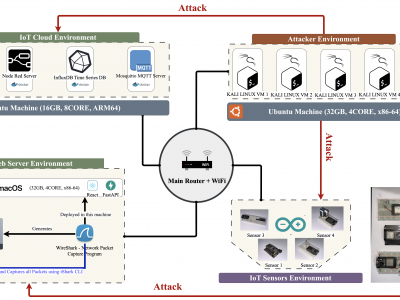
This paper presents an enhanced methodology for network anomaly detection in Industrial IoT (IIoT) systems using advanced data aggregation and Mutual Information (MI)-based feature selection. The focus is on transforming raw network traffic into meaningful, aggregated forms that capture crucial temporal and statistical patterns. A refined set of 150 features including unique IP counts, TCP acknowledgment patterns, and ICMP sequence ratios was identified using MI to enhance detection accuracy.
- Categories:
 415 Views
415 Views
This dataset is used for machine learning. And the data set is collected in different micro-environments. In this project, ExpoM-RF 4 is used to measure the electric field strength. Four different typs of micro-environments are selected which are urban (6 high population density areas in Kuala Lumpur), suburban (7 low population density areas in Cyberjaya), park (3 park areas) and one indoor micro-environment. From the measurement campaigns, three machine learning (ML) techniques are simulated to model the Electric Field Strength in each micro-environment.
- Categories:
61 Views
This dataset comprises 2 million synthetic samples generated using the Variational Autoencoder-Generative Adversarial Network (VAE-GAN) technique. The dataset is designed to facilitate cardiovascular disease prediction through various demographic, physical, and health-related attributes. It contains essential physiological and behavioral indicators that contribute to cardiovascular health.
Dataset Description The dataset consists of the following features:
- Categories:
307 Views
This dataset comprises 2 million synthetic samples generated using the Variational Autoencoder-Generative Adversarial Network (VAE-GAN) technique. The dataset is designed to facilitate cardiovascular disease prediction through various demographic, physical, and health-related attributes. It contains essential physiological and behavioral indicators that contribute to cardiovascular health.
Dataset Description The dataset consists of the following features:
- Categories:
460 Views
LIVE-Viasat Real-World Satellite QoE Database contains 179 videos from real-world streaming, encompassing a range of distortions. Enhanced by a study with 54 participants providing detailed QoE feedback, our work not only provides a rich analysis of the determinants of subjective QoE but also delves into how various streaming impairments influence user behavior, thereby offering a more holistic understanding of user satisfaction.
- Categories:
13 Views
LIVE-Viasat Real-World Satellite QoE Database contains 179 videos from real-world streaming, encompassing a range of distortions. Enhanced by a study with 54 participants providing detailed QoE feedback, our work not only provides a rich analysis of the determinants of subjective QoE but also delves into how various streaming impairments influence user behavior, thereby offering a more holistic understanding of user satisfaction.
- Categories:
15 Views
Large Vision-Language Models (LVLMs) struggle with distractions, particularly in the presence of irrelevant visual or textual inputs. This paper introduces the Irrelevance Robust Visual Question Answering (IR-VQA) benchmark to systematically evaluate and mitigate this ``multimodal distractibility". IR-VQA targets three key paradigms: irrelevant visual contexts in image-independent questions, irrelevant textual contexts in image-dependent questions, and text-only distractions.
- Categories:
29 Views
Agriculture is the backbone of Mizoram’s state economy as the majority of the people use agriculture and its allied sector as their livelihood. According to the 2011 census, more than 50% of the people are still engaged in agriculture and its related activities. Jhum cultivation or shifting cultivation is the primary farming pattern in the state.
- Categories:
523 Views
The COVID-19 Vaccine Misinformation Aspects Dataset contains 3,822 English tweets discussing COVID-19 vaccine misinformation, collected from Twitter/X between December 31, 2020, and July 8, 2021.
- Categories:
99 Views
This dataset is designed for research on 2D Multi-frequency Electrical Impedance Tomography (mfEIT). It includes:
- Categories:
64 Views