IoT

PPE Usage Dataset
This repository provides the Personal Protective Equipment (PPE) Usage Dataset, designed for training deep neural networks (DNNs). The dataset was collected using the EFR32MG24 microcontroller and the ICM-20689 inertial measurement unit, which features a 3-axis gyroscope and a 3-axis accelerometer.
The dataset includes data for four types of PPE: helmet, shirt, pants, and boots, categorized into three activity classes: carrying, still, and wearing.
- Categories:
 67 Views
67 Views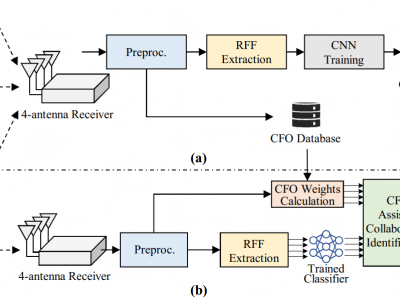
This dataset contains signals collected from 10 commercial-off-the-shelf Wi-Fi devices by an USRP X310 equipped with four receiving antennas. It comprises signals affected by various channel conditions, which is intended for use by the researchers in the development of a channel-robust RFFI system. The preprocessed preamble segments, estimated CFO values and device labels are provided. Please refer to the README document for more detailed information about the dataset.
- Categories:
251 Views
Two publicly available datasets, the PASS and EmpaticaE4Stress databases, were utilised in this study. They were chosen because they both used the same Empatica E4 device, which allowed the acquisition of a variety of signals, including PPG and EDA. The dataset consists of in 1587 30-second PPG segments. Each segment has been filtered and normalized using a 0.9–5 Hz band-pass and min-max normalization scheme.
- Categories:
177 Views
Hyperspectral imaging (HSI) has become a pivotal tool for environmental monitoring, particularly in identifying and analyzing hydrocarbon spills. This study presents an Internet of Things (IoT)-based framework for the collection, management, and analysis of hyperspectral data, employing a controlled experimental setup to simulate hydrocarbon contamination. Using a state-of-the-art hyperspectral camera, a dataset of 116 images was generated, encompassing temporal and spectral variations of gasoline, thinner, and motor oil spills.
- Categories:
289 Views
Training and testing the accuracy of machine learning or deep learning based on cybersecurity applications requires gathering and analyzing various sources of data including the Internet of Things (IoT), especially Industrial IoT (IIoT). Minimizing high-dimensional spaces and choosing significant features and assessments from various data sources remain significant challenges in the investigation of those data sources. The research study introduces an innovative IIoT system dataset called UKMNCT_IIoT_FDIA, that gathered network, operating system, and telemetry data.
- Categories:
683 Views
The growing demand to address environmental sustainability and climate change has emphasized the need for innovative solutions in supply chain and energy management. This study investigates the transformative role of the Internet of Things (IoT) in reducing carbon footprints and optimizing energy utilization within supply chains. A well-structured methodology was employed including regression modeling, cluster analysis, IoT simulation frameworks and optimization techniques. The data was collected from diverse energy and emission databases.
- Categories:
169 Views
Generalized cross-domain sensing is a crucial step in driving the Internet of Everything. This dataset provides CSI information of Wi-Fi for different recognition tasks (gesture vs. gait) as well as DFS and (Absolute Distance Profile) ADP for researchers to validate the ADP. The ADP was tested on both the CNN-RNN networks that we utilized with parameter settings comparable to Widar 3.0, trained for 100 cycles. Then, we attach the confusion matrix for different tasks, which has been shown in the folder of the same level as the dataset, and you can refer to it for your reference.
- Categories:
339 Views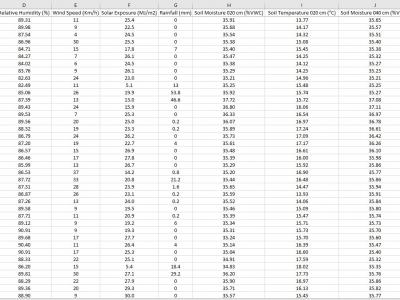
The data is collected from the deployed IoT sensor node at a pilot farm in Narrabri, Australia. The dataset includes information about soil characteristics such as soil moisture and soil temperature at 20-40-60 cm depth. The sensor node also provides information about environmental influencers, which are critical in constructing machine learning models to predict Evapotranspiration in diverse soil and environmental conditions.
- Categories:
777 Views
The necessity for strong security measures to fend off cyberattacks has increased due to the growing use of Industrial Internet of Things (IIoT) technologies. This research introduces IoTForge Pro, a comprehensive security testbed designed to generate a diverse and extensive intrusion dataset for IIoT environments. The testbed simulates various IIoT scenarios, incorporating network topologies and communication protocols to create realistic attack vectors and normal traffic patterns.
- Categories:
315 Views
With the accelerating pace of population aging, the urgency and necessity for elderly individuals to control smart home systems have become increasingly evident. Smart homes not only enhance the independence of older adults, enabling them to complete daily activities more conveniently, but also ensure safety through health monitoring and emergency alert systems, thereby reducing the caregiving burden on families and society.
- Categories:
161 Views