IoT

A novel ultra-low-voltage (ULV) Dual-EdgeTriggered (DET) flip-flop based on the True-Single-PhaseClocking (TSPC) scheme is presented in this paper. Unlike Single-Edge-Triggering (SET), Dual-Edge-Triggering has the advantage of operating at the half-clock rate of the SET clock. We exploit the TSPC principle to achieve the best energy-efficient figures by reducing the overall clock load (only to 8 transistors) and register power while providing fully static, contention-free functionality to satisfy ULV operation.
- Categories:
 32 Views
32 Views
MobRFFI is a WiFi device fingerprinting and re-identification dataset collected in the Orbit testbed facility in July and April 2024. The dataset contains raw IQ samples of WiFi transmissions captured at 25 Msps on channel 11 (2462 MHz) in the 2.4 GHz band, using Ettus Research N210r4 USRPs as receivers and a set of WiFi nodes equipped with Atheros AR5212 chipsets as transmitters. The data collection spans two days (July 19 and August 8, 2024) and includes 12,068 capture files totaling 5.7 TB of data.
- Categories:
154 Views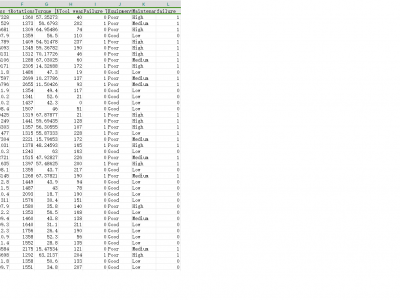
The Machine Failure Predictions Dataset (D_2) is a real-world dataset sourced from Kaggle, containing 10,000 records and 14 features pertinent to IIoT device performance and health status. The binary target feature, 'failure', indicates whether a device is functioning (0) or has failed (1). Predictor variables include telemetry readings and categorical features related to device operation and environment. Data preprocessing included aggregating features related to failure types and removing non-informative features such as Product ID.
- Categories:
339 Views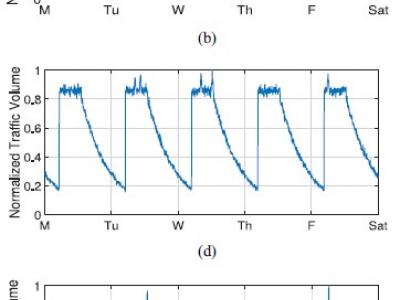
This dataset provides realistic Internet of Things (IoT) traffic time-series data generated using the novel Tiered Markov-Modulated Stochastic Process (TMMSP) framework. The dataset captures the unique temporal dynamics and stochastic characteristics of three distinct IoT applications: smart city, eHealth, and smart factory systems. Each application's traffic pattern reflects real-world behaviors including human-machine correlation (HMC), sudden data bursts, and application-specific seasonality patterns.
- Categories:
835 Views
With the rapid development of IoT technology, IoT-enabled systems, represented by smart homes, are becoming ubiquitous. In order to support personalized user requirements, such systems appeal to the end-user programming paradigm. This paradigm allows end-users to describe their requirements using TAP (Trigger-Action Programming) rules, which can be deployed on demand. However, writing TAP rules is error-prone and end-users are often unaware of the actual effects of the rules they write, given the context-sensitive nature of these effects.
- Categories:
39 Views
Now days, everything in the world is almost becoming automated. Technology has changed the view through which earlier we used to look at the objects. In the 21st century, we are now opting for more easy options for accessing the technology and day to day objects. The best example is banking where in previous days; the account holder had to go far to the bank and stand in the queue and then transfer or cash the money. But same is now possible on even a basic cell phone where you can transfer the cash, pay the bills very easily not more than five minutes.
- Categories:
161 Views
Graphics provides one of the most natural means of communicating with a computer, since our highly developed 2D Or 3D pattern-recognition abilities allow us to perceive and process pictorial data rapidly. • Computers have become a powerful medium for the rapid and economical production of pictures. • Graphics provide a so natural means of communicating with the computer that they have become widespread. • Interactive graphics is the most important means of producing pictures since the invention of photography and television . • We can make pictures of not only the real world objects but als
- Categories:
27 Views
Tourism receipts worldwide are not expected to recover to 2019 levels until 2023. In
the first half of this year, tourist arrivals fell globally by more than 65 percent, with a near halt
since April—compared with 8 percent during the global financial crisis and 17 percent amid
the SARS epidemic of 2003, according to ongoing IMF research on tourism in a post-pandemic
world. Because of pandemic we faces the different struggles specially the business closed.
that’s why country’s economy decrease, at first many company need to reduce their employee.
- Categories:
105 Views
The data set includes attack implementations in an Internet of Things (IoT) context. The IoT nodes use Contiki-NG as their operating system and the data is collected from the Cooja simulation environment where a large number of network topologies are created. Blackhole and DIS-flooding attacks are implemented to attack the RPL routing protocol.
The datasets includes log file output from the Cooja simulator and a pre-processed feature set as input to an intrusion detection model.
- Categories:
668 Views
The Theory of Integrated Language Learning (ToILL) supports many complementary schools of educational thought. The constructivism, pragmatism, humanism, and sociocultural theory are combined in one process to produce an integrated and successful method of language acquisition. The approach promotes the complete person development in a continuously changing environment that is global in nature but does not stop at cognitive components but also concerns the social and emotional experiences of the students.
- Categories:
263 Views