IoT
The data used in this work is collected using the AirBox Sense system developed to detect six air pollutants, ambient temperature, and ambient relative humidity. The pollutants are Nitrogen Dioxide (NO2), surface Ozone (O3), Carbon Monoxide (CO), Sulphur Dioxide (SO2), Particulate Matter (PM2.5, and PM10). The sensors monitor these pollutants in real-time and store them in a cloud-based platform using a cellular module. Data are collected every 20 seconds, producing 4320 readings each day.
- Categories:
 283 Views
283 Views
This dataset presents real-world VPN encrypted traffic flows captured from five applications that belong to four service categories, which reflect typical usage patterns encountered by everyday users.
Our methodology utilized a set of automatic scripts to simulate real-world user interactions for these applications, to achieve a low level of noise and irrelevant network traffic.
The dataset consists of flow data collected from four service categories:
- Categories:
468 Views
DALHOUSIE NIMS LAB BENIGN DATASET 2024-2 dataset comprises data captured from Consumer IoT devices, depicting three primary real-life states (Power-up, Idle, and Active) experienced by everyday users. Our setup focuses on capturing realistic data through these states, providing a comprehensive understanding of Consumer IoT devices.
The dataset comprises of nine popular IoT devices namely
Amcrest Camera
Smarter Coffeemaker
Ring Doorbell
Amazon Echodot
Google Nestcam
Google Nestmini
Kasa Powerstrip
- Categories:
202 Views
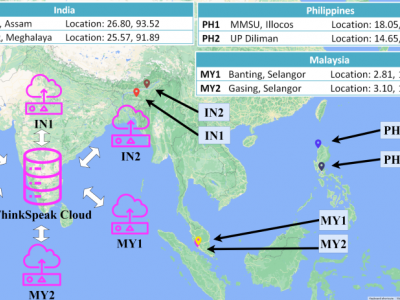
Data Collection Period: Both datasets cover the period from July 1, 2022, to July 31, 2023. This one-year span captures a full cycle of seasonal variations, which are critical for understanding and forecasting air quality trends.
Data Characteristics
- Temporal Resolution: The data is recorded at 15-minute intervals, offering detailed temporal resolution.
- Missing Data: Both datasets contain missing values due to sensor malfunctions or communication issues. These missing values were handled using imputation techniques as part of the preprocessing phase.
- Categories:
447 Views
This dataset is designed for the reconstruction of images of underground potato tubers using received signal strength (RSS) measurements collected by a ZigBee wireless sensor network. It includes RSS data from sensing areas of various sizes, environments with different layouts, and soils with varying moisture levels. The measurements were obtained from 9 potato tubers of differing sizes and shapes, which were buried in two distinct positions within the sensing area.
- Categories:
230 Views
The security of Internet of Things (IoT) networks has become a major concern in recent years, as the number of connected objects continues to grow, thereby opening up more potential for malicious attacks. Supervised Machine Learning (ML) algorithms, which require a labeled dataset for training, are increasingly employed to detect attacks in IoT networks. However, existing datasets focus only on specific types of attacks, resulting in ML-based solutions that struggle to generalize effectively.
- Categories:
378 Views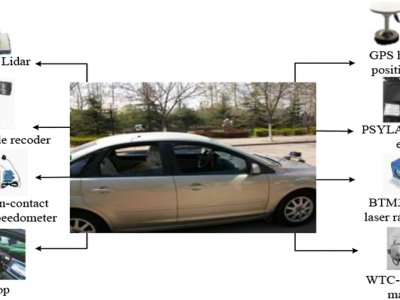
The "Aggressive Driving Behavior IoT Data" dataset captures real-time driving behaviour through a network of Internet of Things (IoT) devices, specifically designed to monitor and analyze aggressive driving patterns. This dataset contains comprehensive recordings from various sensors embedded in vehicles, including GPS, accelerometer, gyroscope, and onboard diagnostics (OBD) systems. The data points collected provide detailed insights into vehicle speed, acceleration, braking, steering patterns, and environmental conditions over time.
- Categories:
1557 Views
This study investigates the application of advanced machine learning models, specifically Long Short-Term Memory (LSTM) networks and Gradient Booster models, for accurate energy consumption estimation within a Kubernetes cluster environment. It aims to enhance sustainable computing practices by providing precise predictions of energy usage across various computing nodes. Through meticulous analysis of model performance on both master and worker nodes, the research reveals the strengths and potential applications of these models in promoting energy efficiency.
- Categories:
513 Views
This project aims to generate smart home IoT datasets (especially Zigbee traffic data) in order to support research on smart home IoT network and device profiling, behaviour modelling, characterization, and security analysis. The Zigbee traffic data is captured in a real house with two Zigbee networks containing over 25 Zigbee devices which monitor the daily activities inside the house. The captured Ethernet traffic data from Home Assistant also contains the status data of several non-Zigbee IoT devices such as printers, a smart thermostat, and entertainment devices.
- Categories:
2216 Views
In this dataset we release the data of a sequence of boxes that go through a physical binary sorter that acts as a load balancer between warehouses. This particular physical binary sorter works in real-time operating 4.5 million boxes per year. This is a particular example for a company with hundreds of \textit{physical binary sorters} that are central to the internal logistics of the business.
- Categories:
749 Views