Machine Learning

The CoVID19-FNIR dataset contains news stories related to CoVID-19 pandemic fact-checked by expert fact-checkers. CoVID19-FNIR is a CoVID-19-specific dataset consisting of fact-checked fake news scraped from Poynter and true news from the verified Twitter handles of news publishers. The data samples were collected from India, The United States of America, and European regions and consist of online posts from social media platforms between February 2020 to June 2020. The dataset went through prepossessing steps that include removing special characters and non-vital information.
- Categories:
 6730 Views
6730 Views
The accompanying dataset for the CVSports 2021 paper: DeepDarts: Modeling Keypoints as Objects for Automatic Scoring in Darts using a Single Camera
Paper Abstract:
- Categories:
7978 Views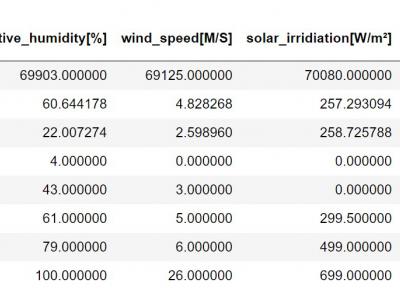
The heating and electricity consumption data are the results of an energy audit program aggregated for multiple load profiles of a residential customer. These profiles include HVAC systems loads, convenience power, elevator, etc. The datasets are gathered between December 2010 and November 2018 with a one-hour timestep resolution, thereby containing 140,160 measurements, half of which is for heat or electricity. In addition to the historical energy consumption values, a concatenation of weather variables is also available.
- Categories:
8080 Views
Rembrandt contains data generated through the Glioma Molecular Diagnostic Initiative from 874 glioma specimens comprising approximately 566 gene expression arrays, 834 copy number arrays, and 13,472 clinical phenotype data points. These data are currently housed in Georgetown University's G-DOC System and are described in a related manuscript .
- Categories:
457 Views
The DroneDetect dataset consists of 7 different models of popular Unmanned Aerial Systems (UAS) including the new DJI Mavic 2 Air S, DJI Mavic Pro, DJI Mavic Pro 2, DJI Inspire 2, DJI Mavic Mini, DJI Phantom 4 and the Parrot Disco. Recordings were collected using a Nuand BladeRF SDR and using open source software GNURadio. There are 4 subsets of data included in this dataset, the UAS signals in the presence of Bluetooth interference, in the presence of Wi-Fi signals, in the presence of both and with no interference.
- Categories:
15218 Views
The objective of this dataset is the fault diagnosis in diesel engines to assist the predictive maintenance, through the analysis of the variation of the pressure curves inside the cylinders and the torsional vibration response of the crankshaft. Hence a fault simulation model based on a zero-dimensional thermodynamic model was developed. The adopted feature vectors were chosen from the thermodynamic model and obtained from processing signals as pressure and temperature inside the cylinder, as well as, torsional vibration of the engine’s flywheel.
- Categories:
5186 Views
Cyber-physical systems (CPS) have been increasingly attacked by hackers. Recent studies have shown that CPS are especially vulnerable to insider attacks, in which case the attacker has full knowledge of the systems configuration. To better prevent such types of attacks, we need to understand how insider attacks are generated. Typically, there are three critical aspects for a successful insider attack: (i) Maximize damage, (ii) Avoid detection and (iii) Minimize the attack cost.
- Categories:
316 Views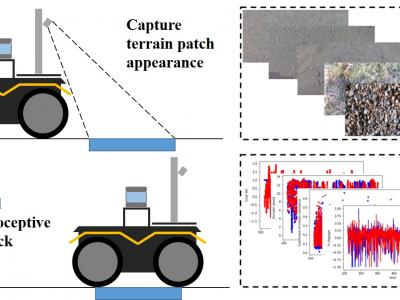
The Jackal UGV, from Clearpath Robotics, was used as the data collecting platform. This skid-steer four-wheel-drive vehicle comes with an onboard IMU, two DC motors with encoders that measure wheel angular speeds, and current sensors that measure motor current outputs. On each side of the robot, the front wheel and back wheel are jointed with a gearbox and so spin together at the same rate and direction. The IMU provided vehicle attitude measurements in terms of Euler angles, as well as linear acceleration and angular rate of the vehicle body in three Euclidean axes.
- Categories:
1267 Views
The data set contains 152 measurements of room impulse responses for direction of arrival estimation, using a compact three-channel microphone array. Sources are placed at 10-degree intervals from -90 to 90 degrees in the azimuth plane at range 150 cm. There are also 5 off-grid measurement positions and 6 off-range positions - at ranges 1 m, 2 m, 2.5 m and 3 m. The measurements are performed in a furnished classroom, which is approximately rectangular and of dimensions 9 x 6 x 3 m. The reverberation time is 0.4 s.
- Categories:
929 Views
The dermoscopic images considered in the paper "Dermoscopic Image Classification with Neural Style Transfer" are available for public download through the ISIC database (https://www.isic-archive.com/#!/topWithHeader/wideContentTop/main). These are 24-bit JPEG images with a typical resolution of 768 × 512 pixels. However, not all the images in the database are in satisfactory condition.
- Categories:
1662 Views