Machine Learning


The dataset contains 4600 samples of 12 different hand-movement gestures. Data were collected from four different people using the FMCW AWR1642 radar. Each sample is saved as a CSV file associated with its gesture type.
- Categories:
 4473 Views
4473 Views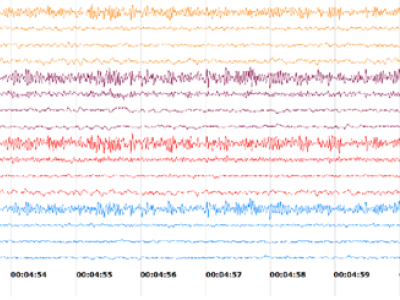
This dataset consists of EEG data of 40 epileptic seizure patients (both male and female) of age from 4 to 80 years. The raw data was collected from Allengers VIRGO EEG machine at Medisys Hospitals, Hyderabad, India. The EEG electrodes were placed according to 10 – 20 International standard. The EEG data was recorded from 16 channels (FP2-F4, F4-C4, C4-P4, P4-O2, FP1-F3, F3-C3, C3-P3, P3-O1, FP2-F8, F8-T4, T4-T6, T6-O2, FP1-F7, F7-T3, T3-T5, and T5-O1) at 256 samples per second.
- Categories:
11810 Views
Reverse transcription-polymerase chain reaction (RT-PCR) is currently the gold standard in COVID-19 diagnosis. It can, however, take days to provide the diagnosis, and false negative rate is relatively high. Imaging, in particular chest computed tomography (CT), can assist with diagnosis and assessment of this disease. Nevertheless, it is shown that standard dose CT scan gives significant radiation burden to patients, especially those in need of multiple scans.
- Categories:
3155 Views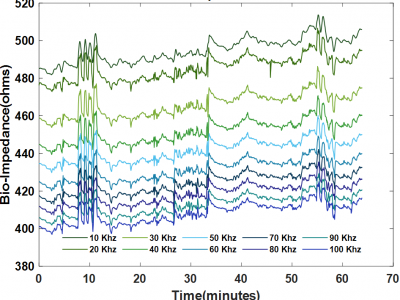
This dataset is taken from 20 subjects over a duration of 1 hour where experiments were done on the upper body bio-impedance with the following objectives:
a) Evaluate the effect of externally induced perturbance at the SE interface caused by motion, applied pressure, temperature variation and posture change on bio-impedance measurements.
b) Evaluate the degree of distortion due to artefact at multiple frequencies (10kHz-100kHz) in the bio-impedance measurements.
- Categories:
619 Views

The AOLAH databases are contributions from Aswan faculty of engineering to help researchers in the field of online handwriting recognition to build a powerful system to recognize Arabic handwritten script. AOLAH stands for Aswan On-Line Arabic Handwritten where “Aswan” is the small beautiful city located at the south of Egypt, “On-Line” means that the databases are collected the same time as they are written, “Arabic” cause these databases are just collected for Arabic characters, and “Handwritten” written by the natural human hand.
- Categories:
1046 ViewsSome 6G use cases include augmented reality and high-fidelity holograms, with this information flowing through the network. Hence, it is expected that 6G systems can feed machine learning algorithms with such context information to optimize communication performance. This paper focuses on the simulation of 6G MIMO systems that rely on a 3-D representation of the environment as captured by cameras and eventually other sensors. We present new and improved Raymobtime datasets, which consist of paired MIMO channels and multimodal data.
- Categories:
414 Views
LATIC is focusing on non-native Mandarin Chinese learners. It is an annotated non-native speech database for Chinese, which is fully open-source can get online for any purpose use. The related using area can be automatic speech scoring, evaluation, derivation—L2 teaching, Education of Chinese as Foreign Language, etc. We are aiming to provide a relatively small-scale and highly efficient training deviation dataset. For this target, four chosen non-native Chinese speaker participated in this project, and their mother tongue (L1s) varies from Russian, Korean, French and Arabic.
- Categories:
1874 Views
Recent advances in computational power availibility and cloud computing has prompted extensive research in epileptic seizure detection and prediction. EEG (electroencephalogram) datasets from ‘Dept. of Epileptology, Univ. of Bonn’ and ‘CHB-MIT Scalp EEG Database’ are publically available datasets which are the most sought after amongst researchers. Bonn dataset is very small compared to CHB-MIT. But still researchers prefer Bonn as it is in simple '.txt' format. The dataset being published here is a preprocessed form of CHB-MIT. The dataset is available in '.csv' format.
- Categories:
13304 Views