Deep Learning

The use of technology in cricket has seen a significant increase in recent years, leading to overlapping computer vision-based research efforts. This study aims to extract front pitch view shots in cricket broadcasts by utilizing deep learning. The front pitch view (FPV) shots include ball delivery by the bowler and the stroke played by the batter. FPV shots are valuable for highlight generation, automatic commentary generation and bowling and batting techniques analysis. We classify each broadcast video frame as FPV and non-FPV using deep-learning models.
- Categories:
 63 Views
63 Views
Plant diseases remain a significant threat to global agriculture, necessitating rapid and
accurate detection to minimize crop loss. This paper presents a lightweight, end-to-end system for plant
leaf disease detection and severity estimation, optimized for real-time field deployment. We propose a
custom Convolutional Neural Network (CNN), built using PyTorch, trained on the PlantVillage dataset
to classify leaves as healthy or diseased with a test accuracy of 92.06%. To enhance its practical relevance,
- Categories:
37 Views
This paper proposed a PE-VAE-GAN network that adaptively selected image reconstruction networks based on flow pattern classification, significantly improving the quality of Electrical Resistance Tomography (ERT) reconstructed images.To address insufficient feature extraction from voltage data,we presented a pseudo-image encoding method that converted the one-dimensional voltage signals into the two-dimensional grayscale images.
- Categories:
15 Views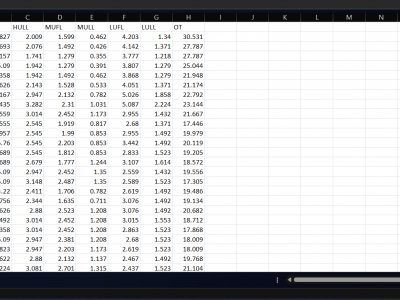
This dataset is a unified compilation of the Electricity Transformer Temperature (ETT) datasets: ETTh1, ETTh2, ETTm1, and ETTm2. It includes both hourly and minute-level temperature and load data collected from power transformers, which are vital for developing and benchmarking time-series forecasting models. The dataset contains features such as high and medium voltage transformer temperatures (HUFL, HULL, MUFL, MULL) and the operational temperature (OT), which serves as the primary prediction target.
- Categories:
152 Views
Hyper-spectral unmixing is a technique to estimate the abundances of different endmembers in each mixed pixel of remote sensing images. Deep learning has made significant progress in this area, offering automatic feature extraction, nonlinear pattern recognition, and end-to-end solutions. However, existing deep learning models have not fully utilized the spectral information of endmembers, leading to insufficient data mining.
- Categories:
36 Views
This dataset integrates textual, financial, and macroeconomic indicators to support research on bank failure prediction and financial distress forecasting in Vietnam. It includes financial news from the BKAI News Corpus Dataset (2009–2023) and financial crisis data from "A Dataset for the Vietnamese Banking System (2002–2021)" (Tu Le et al., 2022), covering crisis-related events such as restructuring, special control, mergers, and acquisitions.
- Categories:
58 Views
Data associated with the article: "PM2.5 Retrieval with Sentinel-5P Data over Europe Exploiting Deep Learning"
- Categories:
23 Views
Māori enterprises are pivotal to the economic and cultural prosperity of Aotearoa, yet predictive analysis of business outcomes tailored to these enterprises remains underexplored. This research examines the application of recurrent neural networks (RNNs) and transformer architectures to forecast key performance indicators (KPIs) for Māori small and medium-sized enterprises (SMEs).
- Categories:
25 Views
This dataset comprises 32-bit floating-point SAR images in TIFF format, capturing coastal regions. It includes corresponding ground truth masks that differentiate between land and water areas. The covered regions include the Netherlands, London, Ireland, Spain, France, Lisbon, the USA, India, Africa, and Italy. The SAR images were acquired in Interferometric Wide (IW) mode with dual polarization at a spatial resolution of 10m × 10m.
- Categories:
309 Views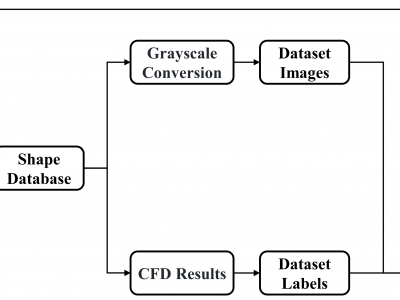
This dataset provides a comprehensive collection of various resources, including the results from Computational Fluid Dynamics (CFD) simulations, the associated CFD processing code, and the dataset along with the source code used for training Convolutional Neural Networks (CNNs). Additionally, it includes data generated by genetic algorithms and the corresponding source code for implementing these algorithms.
- Categories:
151 Views