Deep Learning

Retail Gaze, a dataset for remote gaze estimation in real-world retail environments. Retail Gaze is composed of 3,922 images of individuals looking at products in a retail environment, with 12 camera capture angles.
Each image captures the third-person view of the customer and shelves. Location of the gaze point, the Bounding box of the person's head, segmentation masks of the gazed at product areas are provided as annotations.
- Categories:
 611 Views
611 Views
Minimally-Invasive Surgeries can benefit from having miniaturized sensors on surgical graspers to provide additional information to the surgeons. One such potential sensor is an ultrasound transducer. At long travel distances, the ultrasound transducer can accurately measure its ultrasound wave's time of flight, and from it, classify the grasped tissue. However, the ultrasound transducer has a ringing artifact arising from the decaying oscillation of its piezo element, and at short travel distances, the artifact blends with the acoustic echo.
- Categories:
769 Views
Some novel methods for imaging based on synthetic aperture radar can result in images contaminated by artifacts as a consequence of pushing the limits of the algorithms. In order to mitigate the impact of this artifacts, image translation techniques can be exploited enabling to turn the SAR image into a cleaner one. For this purpose, multiple techniques can be used such as convolutional neural networks or generative adversial networks. However, the training of those systems can require a high number of images, which can be computationally expensive to generate.
- Categories:
307 Views
The anomaly detection in photovoltaic (PV) cell electroluminescence (EL) image is of great significance for the vision-based fault diagnosis. Many researchers are committed to solving this problem, but a large-scale open-world dataset is required to validate their novel ideas. We build a PV EL Anomaly Detection (PVEL-AD) dataset for polycrystalline solar cell, which contains 36,543 near-infrared images with various internal defects and heterogeneous background. This dataset contains anomaly-free images and anomalous images with 10 different categories.
- Categories:
5928 Views
The experiment is based on the open source RSRP data provided by Huawei Technologies Co., LTD. It measures RSRP of 415,244 signal receiving points in 180 dense urban communication cells.
- Categories:
1149 Views
A commonly used definition of spatial disorientation (SD) in aviation is "an erroneous sense of one’s position and motion relative to the plane of the earth’s surface". There exists a wide range of SD use-cases dictated by situational factors, therefore SD has been predominantly studied using reduced motion detection experimental contexts in isolation. The study of SD by use-case makes it difficult to understand general SD occurrence and thus provide viable solutions. To investigate SD in a generalized manner, a two-part Human Activity Recognition (HAR) study was performed.
- Categories:
333 Views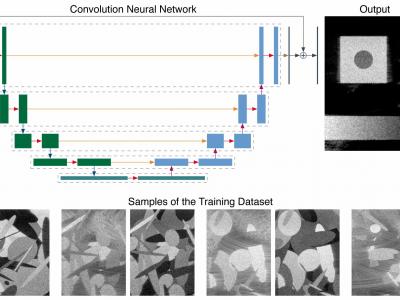
This repository contains the data related to the paper “CNN-Based Image Reconstruction Method for Ultrafast Ultrasound Imaging” (10.1109/TUFFC.2021.3131383). It contains multiple datasets used for training and testing, as well as the trained models and results (predictions and metrics). In particular, it contains a large-scale simulated training dataset composed of 31000 images for the three different imaging configuration considered (i.e., low quality, high quality, and ultrahigh quality).
- Categories:
3115 Views
This dataset is related to dog activity and is sensor data.
- Categories:
691 Views
This LoRa-RFFI project builds a LoRa radio frequency fingerprint identification (RFFI) system based on deep learning techniques. The RF signals are collected from 60 commercial-off-the-shelf LoRa devices. The packet preamble part and device labels are provided. The dataset consists of 19 sub-datasets and please refer to the README document for more detailed collection settings for all the sub-datasets.
- Categories:
7748 Views
ATTENTION: THIS DATASET DOES NOT HOST ANY SOURCE VIDEOS. WE PROVIDE ONLY HIDDEN FEATURES GENERATED BY PRE-TRAINED DEEP MODELS AS DATA
- Categories:
6076 Views